容器隔离软件
1.Docker 的历史
容器技术的快速发展改变了现代软件开发和部署的方式,但是这种技术并不新颖,从很久开始就发展起来了,下面历史是收集而来,简单看一看即可...
1.1.监狱时期
早期的贝尔实验室发明了
chroot,主要是为了避免在一个系统软件编译和安装完成后,需要重写配置环境的情况。因此就考虑能否创建出一个隔离环境,专门用于构建和搭建测试环境,进而得到了一个把进行文件系统隔离的早期容器技术。chroot系统调用可以将进程和子进程的根目录更改为文件系统中的新位置(而不是系统的根目录),隔离之后该进程就无法访问外面的文件,如同一个监狱一样(Chroot Jail),后续只需要把测试信息放在Jail中就可以完成测试了。// 演示关于 chroot() 的使用 #include <unistd.h> #include <stdio.h> #include <stdlib.h> int main() { const char *new_root = "/path/to/new/root"; // 切换根目录 if (chroot(new_root) != 0) { perror("chroot failed"); return 1; } // 切换当前工作目录到新根目录 if (chdir("/") != 0) { perror("chdir failed"); return 1; } // 在新的根目录下执行命令 printf("Now in chrooted environment\n"); // 例如执行一个命令,这里使用 system 函数 system("/bin/sh"); return 0; }到了后来的
FreeBSD Jail让每一个Jail成为在主机上运行的虚拟环境,有自己的文件管理、进程管理、用户管理,甚至还可以为每个虚拟环境分配一个ip地址,使得网络空间也被隔离开来,本质也是一种监狱机制。后面还退出了一种叫
Linux VServer的基于内核的虚拟化技术,可以在单个Linux内核实例上创建多个独立的虚拟环境(称为 安全上下文 或 虚拟服务器)。这些虚拟环境共享相同的内核,但它们在用户空间中是隔离的,每个环境可以有自己的文件系统、网络接口和进程空间。如果您想尝试这种技术,可以安装VServer试一试,这里举一个Ubuntu的大概伪例子。(1)首先您需要一个支持
VServer的内核以及相关的用户空间工具, 这通常需要从源代码编译或从特定的包管理器安装,也就是sudo apt-get install linux-image-vserver vserver-debiantools(2)然后创建新虚拟服务器, 使用
vserver工具来创建和管理虚拟服务器。创建一个新的虚拟服务器实例,并指定其根文件系统sudo vserver <vserver_name> build...(3)使用
sudo vserver <vserver_name> start启动虚拟服务器(4)使用
sudo vserver <vserver_name> enter命令进入虚拟服务器的上下文环境(5)管理虚拟服务器...
Solaris Containers软件公测,结合系统资源控制和区域进行了隔离,增加了快照和克隆功能,但是没有太大的发展(也没有那么强需求的场景),依旧是以Jail模式为核心
1.2.云计算时期
云时代是 Google 率先提出的概念,进而发生了各种云厂商,现代的云已经变成了强需求,变成和水电一样的基础设施。云的存在使得个人或企业无需操心大量数据的处理带来的高资源消耗,用户只需要向云服务厂商花费较低的钱,就可以得到高回报的云资源。云的存在使得隔离技术变成核心的诉求。
Google 推出 Process Containers/Control Groups 被合并到 Linux2.6.24 版本中,旨在限制、统计、隔离一组进程的资源使用(这里的资源包括 CPU, 内存, 磁盘IO, 网络...)。
- 此时控制和隔离技术都发展起来了,顺势就发展起了
LXC这个比较完整的Linxu容器管理技术,其内部使用Control Groups(可以控制一个进程组的资源限制和资源管理)和Linux命名空间namespace来实现(处于不同命名空间的进程组在使用资源的时候,只能感受到自己的资源),可以在单个Linux上运行,无需任何补丁 - 而后推出的
GAE(Goolge App Engine)则首次把开发平台当作一种服务来实现,采用云计算技术,跨越多个服务器和数据中心来虚拟化引用程序。而GAE内部使用了Borg来对容器进行编排和调度
因此早期的 LXC 和 Borg 其实就相当于最早的 Docker 和 k8s,前者是容器技术,后者是编排技术,本文我们重点提及 Docker 及其相关的技术,关于编排技术我们有机会再谈及。
因此,云计算就是提供并管理计算资源的服务,将计算资源和服务通过互联网提供给客户。
1.3.云原生时期
容器技术比较完善了,但是容器技术只是解决了容器化和分发问题,没有解决但是如何让软件自动部署、自动更新、自动发布、自动回滚、监控、镜像部署等问题,道理云原生时代时,特别强调微服务化、容器化、持续交付。
云原生和传统云计算之间有一些显著的区别,以下是它们的主要对比:
- 架构设计 云原生基于微服务架构,应用被拆分成多个独立的、自治的服务,每个服务负责特定的功能。这种设计使得应用程序更易于扩展、维护和更新;传统云通常依赖于单体架构,即整个应用作为一个整体进行部署和管理。这种架构可能导致单点故障,并且难以进行独立的扩展和维护。
- 容器化与虚拟化 云原生广泛使用容器(如
Docker)来打包和部署应用。容器提供了应用的环境隔离,并且支持高效的资源利用和快速的部署。主要依赖虚拟机来部署应用。虚拟机提供了完整的操作系统虚拟化,虽然隔离性较好,但启动速度慢,资源利用率不如容器高效。 - 持续集成与持续交付(CI/CD) 云原生强调持续集成和持续交付的实践,通过自动化工具和管道来实现快速的代码提交、测试和部署,确保高频率的交付和快速反馈;传统云可能使用较为传统的部署方式,手动干预较多,更新和发布的周期较长,自动化程度较低。
- 编排与管理 云原生使用动态编排工具如 Kubernetes 来自动管理容器的部署、扩展、负载均衡和故障恢复。这种工具能够高效地管理复杂的分布式应用;传统云通常使用手动的虚拟机管理和配置工具,自动化程度低,管理复杂度高。
- 开发与运维 云原生强调开发(
Dev)和运维(Ops)的紧密结合(DevOps),通过自动化工具和实践实现高效的开发和运营;传统云开发和运维可能分开管理,缺乏一体化的自动化工具,导致部署和运维过程较为复杂和耗时。 - 扩展与弹性 云原生支持弹性扩展,可以根据需求动态增加或减少资源。微服务和容器化使得应用可以轻松地扩展和缩减;传统云扩展通常依赖于虚拟机的增减,可能需要手动干预,并且扩展和缩减的速度较慢。
- 依赖管理 云原生使用服务发现、负载均衡和配置管理等机制来处理服务间的依赖关系和通信;传统云可能依赖于固定的
IP地址和手动配置,处理服务间的依赖和通信更加复杂和不灵活。
因此,云原生就是设计和优化适合在云上运行的应用程序架构,是一种应用开发和部署模式。
2.Docker 是什么
目前最流行的容器化技术是 Docker,最流行的容器管理服务是 Kubernetes(K8s),应用/服务可以打包为 Docker 镜像,通过 K8s 来动态分发和部署镜像。Docker 镜像可理解为一个刚好能运行应用/服务的最小操作系统,内部存放应用/服务的运行代码。
运行环境根据实际的需要提取设置好后,把整个“小操作系统”打包为一个镜像后,就可以分发到需要部署相关服务的机器上,直接启动 Docker 镜像就可以把服务运行起来,使服务的部署和运维变得非常简单。
Docker 不仅仅是解决了容器化问题,还直接给云厂商提供了解决方案。
可以进一步查看这个视频,我觉得这个 关于 Docker 的视频 讲得不错,并且评论区的一些讨论虽然不是全对,但是足够您了解到一些事情进入深度的思考。
3.Docker 的安装
下面演示在 Ubuntu20.04.4 LTS 下关于 Docker 换阿里源的安装, 呵,那堵墙就是个 sb 玩意
Ubuntu20.04.4 LTS 安装 Docker
# 更新包管理器并且安装必要的依赖包
$ sudo apt-get update && sudo apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg \
lsb-release
# 添加 Docker 的 GPG 密钥
$ curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
# 如果您可以使用官方源: curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
# 添加 Docker 软件源
echo \
"deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://mirrors.aliyun.com/docker-ce/linux/ubuntu \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# 如果您可以使用官方源:
# echo \
# " deb [arch = amd64 signed-by =/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu \
# $(lsb_release -cs) stable " | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
# 更新包管理器并且开始安装 Docker
sudo apt-get update && sudo apt-get install docker-ce docker-ce-cli containerd.io docker-compose-plugin -y
# 验证 Docker 安装版本
docker --version
Docker version 27.1.1, build 6312585重要
补充:另外,如果有需要的话,还可以给 Docker 配置代理,如果没有魔法的伙伴就可以直接跳过了(不过我觉得按照现在的情况没有魔法可能连 Docker 都用不顺畅...总之您多保重)。
docker pull 命令是由 dockerd 守护进程执行。而 dockerd 守护进程是由 systemd 管理。因此,如果需要在执行 docker pull 命令时使用 HTTP/HTTPS 代理,需要通过 systemd 配置。
因此为 Dockerd 创建配置文件夹 sudo mkdir -p /etc/systemd/system/docker.service.d。
# 配置 Docker 的网络
$ sudo mkdir -p /etc/systemd/system/docker.service.d && sudo vim /etc/systemd/system/docker.service.d/http-proxy.conf && sudo cat /etc/systemd/system/docker.service.d/http-proxy.conf
[Service]
Environment="HTTP_PROXY=http://您配置的代理服务:代理端口/"
Environment="HTTPS_PROXY=http://您配置的代理服务:代理端口/"
# 重启 Docker 让配置生效
$ sudo systemctl restart docker另外还可以修改 Docker 的存储目录。
# 配置 Docker 的存储
$ sudo vim /etc/docker/daemon.json && sudo cat /etc/docker/daemon.json
{
"data-root": "<path_value>"
}
# 重启 Docker 让配置生效
$ sudo systemctl restart docker好了好了,先到此为止,我们不再深入怎么使用 Docker 了,我们先探索以下关于 Docker 的原理再来谈及怎么使用的问题。
4.Docker 的原理
历史“废话”结束,接下来开始学习 Docker,可以 查看官方容器引擎文档,因为我们之前下载的 docker cli 工具底层调用的就是 Docker Engine,也就是容器引擎。不嫌弃更新慢的话,查看 Docker 菜鸟文档也是可以的。
4.1.虚拟化容器化原理
- 物理机:真实的计算机
- 虚拟化:从物理机中抽象出来的多台逻辑计算机/虚拟机,每台虚拟机都可以运行不同的操作系统,这些操作系统运行在宿主机器的原生操作系统上,依赖于原生操作系统
- 容器化:又叫“操作系统层虚拟化”,可以将操作系统内核抽象为多个逻辑内核(虚拟内核和虚拟内核之前有可能是不一样的),对于每个实例的拥有者来说,有点像进程地址空间一样,会误以为内核专属于自己,而
docker目前就是容器技术的事实标准(容器技术需要两个基础,一个是通过命名空间控制资源视图,一个是通过控制组限制运行资源)
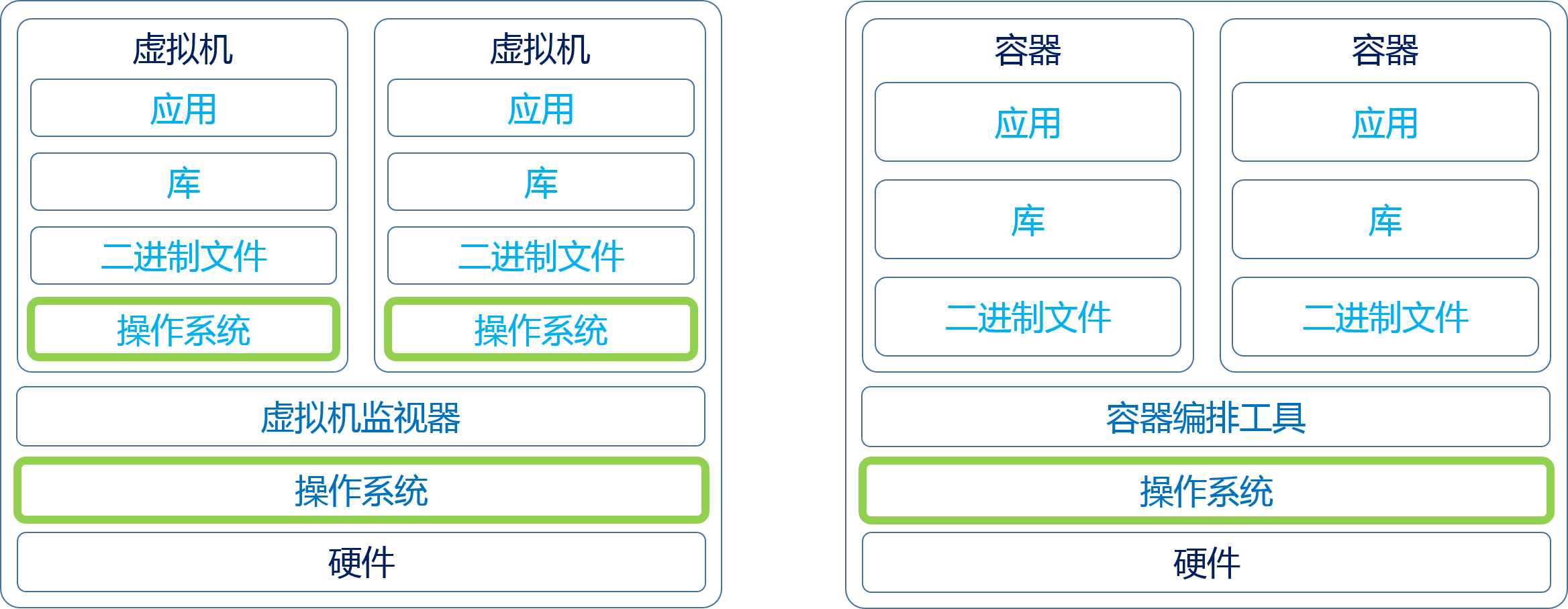
挑重点来说的话就是:
- 虚拟机伪造的是硬件物理接口,进而实现在一个操作系统上加载别的操作系统的源代码
- 而容器伪造的是操作系统接口,进而实现在一个操作系统上模拟其他操作系统系统调用
补充:我们前面提到的虚拟机的实现虚拟机监视器作为宿主机器的软件被调度,而其实也有直接运行在物理机硬件上的虚拟机监视器软件,我们之前使用的
Linxu虚拟机软件Vmware Workstation就属于前者,而Vmware ESX属于后者。
补充:为什么需要虚拟技术或容器技术呢?它们都主要是为了方便以下一些场景:
- 资源细分化利用率高
- 环境标准化保证运行、开发、测试环境一致
- 资源弹性伸缩
- 差异化环境,可以使得不同项目满足不同的系统环境
- 避开不安全软件对整个物理机的影响,也就是沙箱安全
而一旦提及到容器化或 docker,就不得不提及 LXC,而 LXC 底层使用了两种非常重要的技术,一个是命名空间技术,一个是控制组技术。
4.2.命名空间技术原理
命名空间技术 您可以了解下 unshare 指令或接口的使用,这个指令您会使用就明白什么是命名空间了。unshare 指令主要就是为了不共享命名空间而服务的,语法格式为 unshare [options] program [arguments],其底层其实也有配套的系统接口。
[options]如下-i, --ipc不共享IPC(进程通信空间)-m, --mount不共享MOUNT(挂载空间)-n. --net不共享NET(网络空间)-p, --pid不共享PID(进程空间)-u, --uts不共享UTS(UNIX 时间共享空间)-U, --user不共享USER(用户空间)
program可以是任意程序[arguments]如下--fork执行unshare的进程会fork()一个新子进程,在子进程中执行unshare传入的参数,这样子进程内部执行的unshare创建的孙进程在某些情况下(例如创建进程空间不共享的命名空间)就不会因为没有父进程而创建异常--mount-proc执行子进程前,将/pros优先挂载过去,就不会导致命名空间看到同一个/pros进程目录(例如创建进程空间不共享的命名空间,如果看到同一个进程目录就没有意义了)
使用不同的 [options] 可以进入不同的命名空间,如果启动的是 /bin/bash 程序,则可以使用 exit 退出命名空间。
使用 unshare
# UTS 隔离
$ sudo unshare -u /bin/bash # 此时就会有一个子进程 /bin/bash 被创建, 运行在 UTX 不共享的命名空间中
root@bash:/$ pwd
/
root@bash:/$ exit
$ exit
# PID 隔离
$ sudo unshare -p /bin/bash
bash: fork: Cannot allocate memory # 原因是这里的 /bin/bash 虽然是 unshare 的子进程, 但是由于此时进程 ID 和原系统进行了分离, 因此需要创建一个全新的进程, 否则 /bin/bash 就没有父进程无法被创建出来, 导致很多指令无法使用
root@bash:/$ exit # 所以只能退出当前 bash 然后重新想办法创建命名空间
exit
$ sudo unshare -p --fork /bin/bash # 这种方式就可以避免上述的情况
root@bash:/$ ps -ef # 但这里有一个新问题, 为什么 ps -ef 的结果和没有获取命名空间之前是一样的呢? 就是因为 /pros 目录没有提前做挂载而被子进程继承了...
$ exit
$ sudo unshare -p --fork --mount-proc /bin/bash # 此时就可以看到 pid 进行了隔离
root@bash:/$ ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 23:02 pts/2 00:00:00 /bin/bash
root 7 1 0 23:02 pts/2 00:00:00 ps -ef
$ exit
# MOUNT 隔离
sudo unshare --mount --fork /bin/bash
root@bash:/$ dd if=/dev/zero of=data.img bs=8k count=10240
10240+0 records in
10240+0 records out
83886080 bytes (84 MB, 80 MiB) copied, 0.125023 s, 671 MB/s
root@bash:/$ mkfs -t ext4 ./data.img
mke2fs 1.46.5 (30-Dec-2021)
Discarding device blocks: done
Creating filesystem with 20480 4k blocks and 20480 inodes
Allocating group tables: done
Writing inode tables: done
Creating journal (1024 blocks): done
Writing superblocks and filesystem accounting information: done
root@bash:/$ mkdir ./data && mount -t ext4 ./data.img ./data # 这个挂载点在外部是无法被看见的
root@bash:/$ ls
data data.img lost+found
root@bash:/$ cd ./data
root@bash:/$ vim main.cc
root@bash:/$
root@bash:/$ ls
lost+found main.cc
root@bash:/$ exit
exit
root@bash:/$ ls
data data.img limou.txt lost+found
root@bash:/$ cd data
root@bash:/$ ll
total 0重要
补充:不过其实还挺奇葩的,叫命名空间却没有所谓的命名出现。不过 unshare 能得到不共享的命名空间,就说明原本的进程门在某些东西上是共享的,这个共享是偏向系统层次的,因为进程说到底都运行在同一个操作系统上,因此共享某一些东西其实也无可厚非。如果只从进程地址空间空间来看的活,确实是相互独立,因此是共享还是独立要根据视角而定,这里说的共享主要有以下资源。
- MOUNT-文件系统挂载共享 在没有使用
MOUNT命名空间的情况下,系统中的所有进程共享相同的文件系统挂载点和文件系统视图。即所有进程看到的文件系统结构是相同的,都是从根目录开始的目录树。使用MOUNT命名空间后,每个命名空间可以有自己独立的文件系统挂载点。 - NET-网络共享 在没有网络命名空间时,所有进程共享相同的网络接口、
IP地址、路由表。使用NET命名空间后,网络接口和网络配置可以在不同的命名空间中独立存在。 - PID-进程 ID 共享 没有使用
PID命名空间时,系统中的所有进程都有一个全局唯一的PID。使用PID命名空间后,每个命名空间内的进程可以有自己的PID视图,这样同一个PID在不同的命名空间中可能指代不同的进程。 - IPC-进程间通信共享 在没有
IPC命名空间的情况下,所有进程共享同样的IPC资源,如消息队列、信号量和共享内存。使用IPC命名空间后,IPC资源被隔离,不同命名空间的进程无法相互访问IPC资源。 - UTS-主机名共享 在没有
UTS命名空间的情况下,系统中的所有进程共享相同的主机名和域名。使用UTS命名空间后,每个命名空间可以设置独立的主机名和域名。 - USER-用户共享 在没有
USER命名空间的情况下,用户ID和组ID是全局唯一的。使用USER命名空间后,用户和组ID可以在不同的命名空间中映射为不同的值,从而实现更细粒度的权限控制。
4.3.控制组技术的原理
控制组技术则需要通过 mount 指令来实现,不过您需要先使用 cat /proc/filesystems | grep cgroup 查看您的系统是否支持 cgroup,如果是较老版本可能没有显示,或者显示 nodev cgroup,较新的版本还具有 nodev cgroup2。并且可以使用 cat /proc/cgroups 查看可以控制的资源列表(这里面支持的每一种资源也可以叫子系统或者资源控制组,每个子系统代表了一种特定的资源管理功能)。
# 检查 cgroups 的版本
$ cat /proc/cgroups
#subsys_name hierarchy num_cgroups enabled
cpuset 0 118 1
cpu 0 118 1
cpuacct 0 118 1
blkio 0 118 1
memory 0 118 1
devices 0 118 1
freezer 0 118 1
net_cls 0 118 1
perf_event 0 118 1
net_prio 0 118 1
hugetlb 0 118 1
pids 0 118 1
rdma 0 118 1
misc 0 118 1我们把应用了某些资源限制的一组进程的集合称为一个控制组,cgroup 的资源控制非常有趣,是分层设计的,每个层级可以包含多个子系统,每个子系统可以应用不同的资源限制。
那怎么使用控制组呢?首先您需要明白 Linux 提供的控制组 cgroup/cgroup2 其实是一种基于文件系统接口的机制,所以也应该当作一种文件系统来对待,既然是文件系统,就可以把对应的文件系统的设备挂载起来,操作系统一般默认挂载到操作系统下的 /sys/fs/cgroup/ 目录下,不过有可能有的操作系统没有这个行为,您可以自己手动进行挂载。
# 检查是否有默认的挂载目录
$ mount | grep cgroup # 查看是否有挂载点
cgroup2 on /sys/fs/cgroup type cgroup2 (rw,nosuid,nodev,noexec,relatime,nsdelegate,memory_recursiveprot)
$ ls /sys/fs/cgroup # 检查该目录的存在
aegis cgroup.threads io.cost.qos sys-fs-fuse-connections.mount
aegisMonitor cpu.pressure io.pressure sys-kernel-config.mount
aegisPythonLoder0 cpuset.cpus.effective io.prio.class sys-kernel-debug.mount
cgroup.controllers cpuset.mems.effective io.stat sys-kernel-tracing.mount
cgroup.max.depth cpu.stat memory.numa_stat system.slice
cgroup.max.descendants dev-hugepages.mount memory.pressure user.slice
cgroup.procs dev-mqueue.mount memory.stat
cgroup.stat init.scope misc.capacity
cgroup.subtree_control io.cost.model proc-sys-fs-binfmt_misc.mount如果不存在这个目录,那就使用这条指令进行手动挂载,不过有个比较重要的问题是,实际上没有一种设备是属于 cgroup/cgroup2 这种设备因此实际上我们设备使用 none 作为占位符就行,不用把任何文件或设备进行挂载。
# 手动挂载(如果您的系统已挂载了则无需操作这一步)
sudo mkdir -p /sys/fs/cgroup/ && sudo mount -t cgroup2 none /sys/fs/cgroup然后我们才能开始创建一个控制组,如下进行操作即可。
# 创建控制组并且配置限制条件
# 创建一个控制组并且打开
sudo mkdir /sys/fs/cgroup/my_group/ && cd /sys/fs/cgroup/my_group/
# 了解在控制组目录下的配置文件(以下文件您可以在通过 tree | grep "..." 的形式查看系统内其他的控制组是怎么设置的, 另外不同版本的 cgroup 有可能文件名后缀不同, 这里演示的是 cgroup2 的)
# /sys/fs/cgroup/<controller>/cgroup.procs: 这个配置文件用于列出属于该控制组的所有进程 pid, 您可以将进程 pid 写入到这个文件中来将进程加入到该控制组中, 并且使用换行区分不同的进程 pid
# /sys/fs/cgroup/<controller>/memory.max: 设置控制组的最大内存使用限制, 写入 -1 则代表无限制, 若写入其他正整数值 num 则代表不得超过 num byte
# /sys/fs/cgroup/<controller>/cpu.max: 设置控制组的 CPU 使用限制, 写入 <max> <period>, 其中 <max> 表示允许的最大 CPU 时间(以微秒为单位), <period> 表示计算 CPU 使用时间的周期(以微秒为单位), 整体代表每 period 周期内最多可以运行的 max 时间长度的 CPU 时间。特殊的, 如果写入 max 100000 则代表没有限制
# /sys/fs/cgroup/<controller>/pids.max: 设置控制组中可以创建的最大进程数, 直接写入一个正整数值即可。特殊的, 如果写入 max 则代表没有限制
# /sys/fs/cgroup/<controller>/io.max: 设置 IO 设备的限制,例如读写速率限制, 写入 <READ_RATE> <WRITE_RATE>, 分别指读和写的速率限制(以字节每秒为单位)。特殊的, max max 代表对读写毫无限制
# /sys/fs/cgroup/<controller>/cgroup.subtree_control: 在 cgroup 中控制启用或禁用某个子系统, 也就是随时启用和禁用某种资源限制, 书写格式例如 +memory +cpu 代表启用 memory 和 cpu 子系统, -memory 代表禁用 memory 子系统
# ...
$ ls -al # 可以看到我们仅仅是创建了一个 my_group 目录, 内部却自动创建了很多上述描述的配置文件, 如果您发现文件的名字或后缀有些不一样, 可能就是因为内核版本不同带来的 cgroup 版本不同带来的问题
$ ls
cgroup.controllers cgroup.type cpu.stat memory.current memory.stat
cgroup.events cpu.idle cpu.uclamp.max memory.events memory.swap.current
cgroup.freeze cpu.max cpu.uclamp.min memory.events.local memory.swap.events
cgroup.kill cpu.max.burst cpu.weight memory.high memory.swap.high
cgroup.max.depth cpu.pressure cpu.weight.nice memory.low memory.swap.max
cgroup.max.descendants cpuset.cpus io.max memory.max pids.current
cgroup.procs cpuset.cpus.effective io.pressure memory.min pids.events
cgroup.stat cpuset.cpus.partition io.prio.class memory.numa_stat pids.max
cgroup.subtree_control cpuset.mems io.stat memory.oom.group
cgroup.threads cpuset.mems.effective io.weight memory.pressure
# 不过这里我不测试所有的情况, 使用 stress 测压指令来简单测试内存控制和 CPU 控制的情况
$ echo "20971520" > memory.max # 配置内存限制为 20 MB
$ echo "30000 100000" > cpu.max # 配置 CPU 使用率限制为 30%
# 启用内存子系统, 让内存限制生效(同时关闭 CPU 限制, 避免影响)
$ echo "+memory -cpu" > cgroup.subtree_control
# 在启动一个测压进程进行测试
$ stress -m 1 --vm-bytes 50M &
# 查看 stress 的 pid 具体值
$ ps -aux | grep stress
root 9503 0.0 0.0 3708 1400 pts/1 S 14:06 0:00 stress -m 1 --vm-bytes 50M
root 9505 80.7 0.1 54912 3804 pts/1 R 14:06 0:03 stress -m 1 --vm-bytes 50M
root 9515 0.0 0.0 6480 2308 pts/1 S+ 14:06 0:00 grep --color=auto stress
# 添加 pid 到控制组中的管理文件中(两个都添加进去)
$ echo "9503\n9505" > cgroup.procs
# 再次观察可以发现测压进程消失了...
$ ps -aux | grep stress
# 启用 CPU 子系统, 让 CPU 限制生效(同时关闭内存限制, 避免影响)
$ echo "-memory +cpu" > /sys/fs/cgroup/my_cgroup/cgroup.subtree_control
# 在后台启动一个测压进程进行测试
$ stress -c 1 &
# 查询测压进程的 PID 并且添加到测试组管理中
$ ps -aux | grep stress # 查看 stress 的 pid 具体值
root 2332 0.0 0.0 3708 1400 pts/1 S 14:06 0:00 stress -m 1 --vm-bytes 50M
root 2334 80.7 0.1 54912 3804 pts/1 R 14:06 0:03 stress -m 1 --vm-bytes 50M
root 1101 0.0 0.0 6480 2308 pts/1 S+ 14:06 0:00 grep --color=auto stress
# 添加 pid 到控制组中的管理文件中
$ echo "2332\2334" > /sys/fs/cgroup/my_cgroup/cgroup.procs
# 再次观察可以发现测压进程消失了...
$ ps -aux | grep stress重要
补充:上述过程我还是没有试验出来,很离谱 Linux 哪怕是我使用 root 也无法写入,以后换 cgroup v1 试试,待补充...
注
吐槽:有时会看到把两者都当作虚拟技术的情况,这种应该是认为两者实际上都是伪装术,只不过伪装的颗粒度不同的,因此统称为虚拟技术确实是可以的。另外还有一种模拟函数库的虚拟技术,最有名的就是 Java 的 JVM 虚拟机,模拟的就是函数库的接口,也就可以做到所谓的“一处运行,到处跑”。
4.3.LXC 的底层原理
Linux Containers 简称为 LXC,实际上是依赖于 Linux 的命名空间、控制组等技术来构成的一个软件工具,可以认为 Docker 是其增强版本的软件,因此学习 LXC 可以一定程度迁移到 Docker 中。LXC 创建容器的过程要比直接调用底层的接口要来的方便,在 Ubuntu 中可以通过 sudo apt-get install lxc 的方式安装并且使用。
# 安装 lxc 并且检查和查看一些配置
# 安装并且检查是否运行中
$ sudo apt-get install lxc -y
$ systemctl status lxc
● lxc.service - LXC Container Initialization and Autoboot Code
Loaded: loaded (/lib/systemd/system/lxc.service; enabled; vendor preset: enabled)
Active: active (exited) since Mon 2024-08-12 16:15:32 CST; 2min 38s ago
Docs: man:lxc-autostart
man:lxc
Process: 14503 ExecStartPre=/usr/lib/x86_64-linux-gnu/lxc/lxc-apparmor-load (code=exited, status=0/SUCCES>
Process: 14508 ExecStart=/usr/lib/x86_64-linux-gnu/lxc/lxc-containers start (code=exited, status=0/SUCCES>
Main PID: 14508 (code=exited, status=0/SUCCESS)
CPU: 14ms
# 检查 lxc 当前的配置
$ lxc-checkconfig
LXC version 5.0.0
Kernel configuration not found at /proc/config.gz; searching...
Kernel configuration found at /boot/config-5.15.0-113-generic
--- Namespaces ---
Namespaces: enabled # 命名空间功能已启用, 支持容器隔离
Utsname namespace: enabled # 主机名空间已启用, 容器可以有独立的主机名
Ipc namespace: enabled # IPC 命名空间已启用, 容器可以有独立的进程间通信
Pid namespace: enabled # PID 命名空间已启用, 容器可以有独立的进程 ID
User namespace: enabled # 用户命名空间已启用, 容器可以有独立的用户 ID 映射
Network namespace: enabled # 网络命名空间已启用, 容器可以有独立的网络堆栈
--- Control groups ---
Cgroups: enabled # 控制组功能已启用, 支持资源管理和限制
Cgroup namespace: enabled # Cgroup 命名空间已启用, 支持 cgroup 命名空间
Cgroup v1 mount points:
Cgroup v2 mount points:
/sys/fs/cgroup # Cgroup v2 的挂载点
Cgroup v1 systemd controller: missing # 缺失, 系统 d 的 cgroup v1 控制器未启用
Cgroup v1 freezer controller: missin # 缺失, cgroup v1 冻结控制器未启用
Cgroup ns_cgroup: required # 需要, 容器需要 cgroup 名称空间
Cgroup device: enabled # 设备控制器已启用, 支持设备控制
Cgroup sched: enabled # 调度器控制器已启用, 支持调度器控制
Cgroup cpu account: enabled # CPU 资源计量控制已启用, 支持 CPU 资源计量
Cgroup memory controller: enabled # 内存控制器已启用, 支持内存控制
Cgroup cpuset: enabled # CPU 集合控制已启用, 支持 CPU 集合控制
--- Misc ---
Veth pair device: enabled, not loaded # 虚拟以太网对设备支持已启用, 但未加载
Macvlan: enabled, not loaded # MAC 虚拟 LAN 支持已启用, 但未加载
Vlan: enabled, not loaded # 虚拟 LAN 支持已启用, 但未加载
Bridges: enabled, loaded # 桥接支持已启用并加载
Advanced netfilter: enabled, loaded # 高级网络过滤支持已启用并加载
CONFIG_IP_NF_TARGET_MASQUERADE: enabled, not loaded # IP 伪装支持已启用, 但未加载
CONFIG_IP6_NF_TARGET_MASQUERADE: enabled, not loaded # IPv6 IP 伪装支持已启用, 但未加载
CONFIG_NETFILTER_XT_TARGET_CHECKSUM: enabled, not loaded # 网络过滤校验和支持已启用, 但未加载
CONFIG_NETFILTER_XT_MATCH_COMMENT: enabled, not loaded # 网络过滤注释支持已启用, 但未加载
FUSE (for use with lxcfs): enabled, not loaded # FUSE 支持已启用, 但未加载
--- Checkpoint/Restore ---
checkpoint restore: enable# 检查点和恢复功能已启用, 支持容器检查点和恢复
CONFIG_FHANDLE: enabled # 文件句柄支持已启用
CONFIG_EVENTFD: enabled # 事件支持已启用
CONFIG_EPOLL: enabled # 事件轮询支持已启用
CONFIG_UNIX_DIAG: enabled # UNIX 诊断支持已启用
CONFIG_INET_DIAG: enabled # IPv4 诊断支持已启用
CONFIG_PACKET_DIAG: enabled # 数据包诊断支持已启用
CONFIG_NETLINK_DIAG: enabled # 网络链接诊断支持已启用
File capabilities:
Note : Before booting a new kernel, you can check its configuration
usage : CONFIG=/path/to/config /usr/bin/lxc-checkconfig # 指定要检查的内核配置文件路径, 或运行 lxc-checkconfig 工具
# 查看 lxc 提供的容器模板(目前有点少...后面再来下载)
$ ls -al /usr/share/lxc/templates
total 56
drwxr-xr-x 2 root root 4096 Aug 12 16:15 .
drwxr-xr-x 6 root root 4096 Aug 12 16:15 ..
-rwxr-xr-x 1 root root 8601 Jan 25 2024 lxc-busybox
-rwxr-xr-x 1 root root 14497 Jan 25 2024 lxc-download
-rwxr-xr-x 1 root root 7178 Jan 25 2024 lxc-local
-rwxr-xr-x 1 root root 10737 Jan 25 2024 lxc-ociLXC 本质上是 Linux 内核容器功能的一个用户空间接口,因此 lxc 本身是运行在用户空间的,它将应用系统打包为一个软件容器,内部可以包含应用软件本身的代码,以及 所需要的操作系统核心和库,通过统一的命名空间和共享 API 来分配不同软件容器的可用资源,进而创建出用户级的独立沙箱环境,使得 Linux 更加快捷创建和管理应用容器。
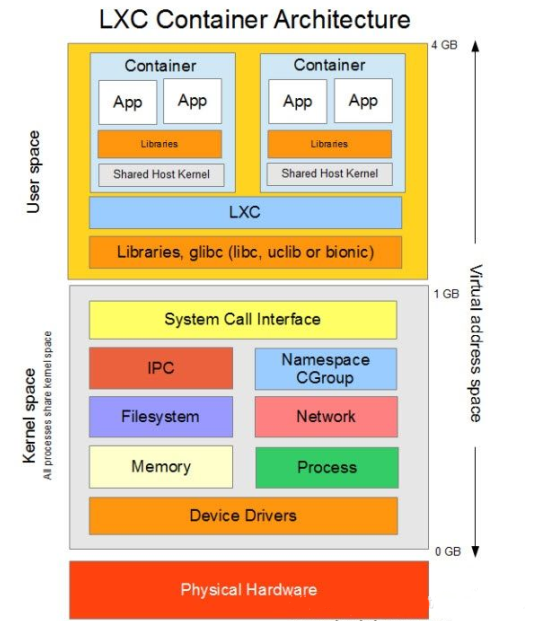
但是,LXC 的弱点也是明显的:
- 隔离性有限 相比虚拟机,
LXC的隔离性较弱,因为容器共享一台主机内核 - 数据迁移困 数据从一个容器中迁移到另一个容器中可能涉及复杂的数据和配置迁移步骤
- 内核依赖高 依赖于主机内核的特性,内核的变化可能影响容器的运行,并且
LXC几乎只支持linux-like的操作系统 - 功能限制多 与完整的虚拟机相比,某些功能和配置选项可能受限
# 简单使用 lxc 创建容器
# 首先我们需要安装 LXC 模板, 我们上面显示出来的模板目录中的内容是比较少的
sudo apt-get install lxc-templates -y
# 查看目前下载好的模板
ls -al /usr/share/lxc/templates
total 528
-rwxr-xr-x 1 root root 13630 Mar 12 2021 lxc-alpine # Alpine Linux
-rwxr-xr-x 1 root root 14170 Mar 12 2021 lxc-altlinux # ALT Linux
-rwxr-xr-x 1 root root 11214 Mar 12 2021 lxc-archlinux # Arch Linux
-rwxr-xr-x 1 root root 8601 Jan 25 2024 lxc-busybox # BusyBox
-rwxr-xr-x 1 root root 30598 Mar 12 2021 lxc-centos # CentOS
-rwxr-xr-x 1 root root 10368 Mar 12 2021 lxc-cirros # Cirros
-rwxr-xr-x 1 root root 26579 Mar 12 2021 lxc-debian # Debian
-rwxr-xr-x 1 root root 14497 Jan 25 2024 lxc-download # Download Template
-rwxr-xr-x 1 root root 41919 Mar 12 2021 lxc-fedora # Fedora
-rwxr-xr-x 1 root root 49755 Mar 12 2021 lxc-fedora-legacy # Fedora Legacy
-rwxr-xr-x 1 root root 28398 Mar 12 2021 lxc-gentoo # Gentoo
-rwxr-xr-x 1 root root 7178 Jan 25 2024 lxc-local # Local Template
-rwxr-xr-x 1 root root 10737 Jan 25 2024 lxc-oci # OCI (Open Container Initiative) Template
-rwxr-xr-x 1 root root 13890 Mar 12 2021 lxc-openmandriva # OpenMandriva
-rwxr-xr-x 1 root root 16701 Mar 12 2021 lxc-opensuse # openSUSE
-rwxr-xr-x 1 root root 41585 Mar 12 2021 lxc-oracle # Oracle Linux
-rwxr-xr-x 1 root root 13865 Mar 12 2021 lxc-plamo # Plamo Linux
-rwxr-xr-x 1 root root 13086 Mar 12 2021 lxc-pld # PLD Linux
-rwxr-xr-x 1 root root 14277 Mar 12 2021 lxc-sabayon # Sabayon Linux
-rwxr-xr-x 1 root root 19148 Mar 12 2021 lxc-slackware # Slackware
-rwxr-xr-x 1 root root 26656 Mar 12 2021 lxc-sparclinux # Sparclinux
-rwxr-xr-x 1 root root 6845 Mar 12 2021 lxc-sshd # SSH Daemon
-rwxr-xr-x 1 root root 26276 Mar 12 2021 lxc-ubuntu # Ubuntu
-rwxr-xr-x 1 root root 11747 Mar 12 2021 lxc-ubuntu-cloud # Ubuntu Cloud
-rwxr-xr-x 1 root root 6009 Mar 12 2021 lxc-voidlinux # Void Linux
$ sudo lxc-create -n my-container -t ubuntu # 格式为 sudo lxc-create -n 创建的容器名字 -t 指定的容器模板
# 繁多的容器初始化信息
##
# The default user is 'ubuntu' with password 'ubuntu'!
# Use the 'sudo' command to run tasks as root in the container.
##
# 上面这里提示的就是默认的用户名为 ubuntu, 密码也是 ubuntu
# 而容器被放到 /var/lib/lxc/<容器名> 这个目录下
$ sudo ls /var/lib/lxc/my-container
config rootfs # config 是容器的配置文件, rootfs 是容器的根目录, 您可以简单查看一下
# 查看容器的配置文件
$ sudo cat /var/lib/lxc/my-container/config
# Template used to create this container: /usr/share/lxc/templates/lxc-ubuntu
# Parameters passed to the template:
# For additional config options, please look at lxc.container.conf(5)
# Uncomment the following line to support nesting containers:
#lxc.include = /usr/share/lxc/config/nesting.conf
# (Be aware this has security implications)
# Common configuration
lxc.include = /usr/share/lxc/config/ubuntu.common.conf
# Container specific configuration
lxc.rootfs.path = dir:/var/lib/lxc/my-container/rootfs
lxc.uts.name = my-container
lxc.arch = amd64
# Network configuration
lxc.net.0.type = veth
lxc.net.0.link = lxcbr0
lxc.net.0.flags = up
lxc.net.0.hwaddr = 00:16:3e:5d:49:40
# 查看容器的根目录结构
$ sudo ls /var/lib/lxc/my-container/rootfs
bin dev home lib32 libx32 mnt proc run srv tmp var
boot etc lib lib64 media opt root sbin sys usr
# 查看创建容器的过程中缓存的软件包(当您想另外建一个一样的容器时, 可以省去很多下载时间)
$ sudo ls /var/cache/lxc
# 列出当前所有的容器
$ sudo lxc-ls -f # -f 表示打印常用的信息
NAME STATE AUTOSTART GROUPS IPV4 IPV6 UNPRIVILEGED
my-container STOPPED 0 - - - false
# 查看某个容器当前的状态
sudo lxc-info -n my-container
Name: my-container
State: STOPPED # 这里显示目前的容器处于停止状态
# 启动容器然后查看容器的状态(可以看到地址、磁盘挂载信息、目录信息都和宿主机不一样)
$ sudo lxc-start -n my-container
$ sudo lxc-info -n my-container
Name: my-container
State: RUNNING
PID: 41456
IP: 10.0.3.227
Link: vethRyGMCs
TX bytes: 1.26 KiB
RX bytes: 1.39 KiB
Total bytes: 2.66 KiB
# 进入容器中, 像使用一台真正主机一样操作容器
sudo lxc-attach -n my-container -- bash # -- 被视为分隔符, 可以用来分割前面的选项和在容器内部执行的命令
root@my-container:/# ls
bin dev home lib32 libx32 mnt proc run srv tmp var
boot etc lib lib64 media opt root sbin sys usr
# 退出容器的 bash
root@my-container:/# exit # 和一般的主机一样使用 exit 或者 [ctrl+d] 即可退出容器的 bash
exit
# 在容器外面把命令交给容器去执行
sudo lxc-attach -n my-container --clear-env -- echo "hello limou" # --clear-env 这个选项可先清除容器中当前的环境变量, 仅保留必要的最小环境变量集, 有助于确保在容器中执行的命令不会受到外部环境影响
hello limou
# 停止容器然后查看查看容器的状态
$ sudo lxc-stop -n my-container
$ sudo lxc-info -n my-container
Name: my-container
State: STOPPED
# 删除容器
sudo lxc-destroy -n my-container此外还有一些比较轻小的指令,作为 Linux 下的快速实验环境还是非常不错的,毕竟容器的根目录树可以任意修改,也不怕系统奔溃。还有其他的指令这里就不再赘述,您可以在网上搜索,或者 访问 LXC 的官网查询一下 即可。
重要
补充:不过只有命名空间技术和控制组技术其实还远远不够构成一个 LXC 软件,还需要其他的技术,有机会以后待补充...
4.4.Docker 本身原理
4.4.1.Docker 早期设计
Docker 狭义理解来说本身其实不是容器,而是 LXC 之类的增强版,是使得容器易用的工具。容器是 Linux 中的技术,但是被 Docker 这项技术推广并且普及了。事实上 Docker 早期就是作为 LXC 的二次封装来发行的。
Docker 是一个用 Go 编写的项目,主要目的是 Build, ship and run any app, anywhere.(在任何地方构建,发布, 运行任何应用程序) 使得用户的应用能一次封装,到处运行。
早期的 Docker 利用 LXC 做容器管理的引擎,但不再像 LXC 一样使用模板来安装生成,而是使用镜像技术,把一个操作系统用户程序所需要的接口库提前编排好并整体打包(build)为 .image 文件。而这些镜像文件会被集中运送(ship)到一个仓库中,当需要创建容器时,Docker 连接镜像服务器(也就是镜像仓库)来下载匹配的镜像文件,再基于镜像直接调用 LXC 的 lxc-create 工具启动容器即可(run)。
因此就是依靠前面的命名空间技术和控制组技术来达成容器化的目的。
4.4.2.Docker 引擎迭代
但是后来的 Docker 组件抛弃了 LXC 容器管理引擎,先后研发了 libcontainer, CNCF, RunC(libcontainer其实就是RunC的核心模块) 目前比较新的 Docker 使用的容器管理引擎就是 RunC,用户是通过 containerd 进行调用的(containerd 的作用和 systemd 类似,都是守护进行,也是由 Docker 官方自己进行维护)。后来,RunC 逐渐变成了容器标准,而和 Google 的第二次竞争中,Google 公司的 k8s 打败了 Docker 公司的 Swarm,成为了编排标准(编排就是对多个容器的管理方案)。
而后来 Docker 公司把 Docker 的命名交给收费版,原来的 Docker 项目改名为 Moby,可以前往 Moby 的官网查看源代码。发展到现在,我们对 Docker 主要有两个称呼,Docker-CE(moby, containerd, runc...) 和 Docker-EE(Docker-CE本身, 其他组件和功能),前者是开源版本,后者是收费版本,可以前往 Docker 官网查看。
至此,我们就需要开始学习如何使用现代的 Docker 了,下面以我们之前下载好的 Docker version 27.1.1 版本作为演示。
4.4.3.Docker 镜像原理
Docker 镜像的本质是一个只读的文件,内部包含文件系统、源代码、库文件、依赖、工具和一些运行镜像 Docker 所需的文件。通过镜像文件可以实例出很多的容器实体(就像一个压缩包)。
镜像文件本质是又多个层构成的,每一个层都是一个文件系统 Union FS,合起来就形成一个虚拟文件系统,每一层都有三种权限(只读、读写、写出),不过镜像文件基本都是设置为只读的。
Docker 会根据一个 dockerfile 来一步步从最低一层开始构建镜像文件,上层的修改会覆盖下层的可见性。
而 Docker 项目最大的贡献就是定义了关于镜像文件分层的存储格式,这种分层非常方便共享,减少存储空间占用,提高可维护性。
因此如果之前的镜像文件中在远端仓库中已经存在,则会进行引用而不用推送,加快传输速度。
重要
补充:理论上我们也可以自己编写镜像文件,不过我们后面再补充...
4.4.4.Docker 容器原理
容器其实就是镜像文件的一份实例化,本质就是操作系统的一个进程,容器有 初建(created), 运行(running), 停止(stopped), 暂停(paused), 删除(deleted) 五种状态。
不过,只有宿主机看得到各个容器的进程列表、环境变量、网络配置等,每一个容器内部只能知道自己的,而无法知道宿主主机的内容。
不过此时容器在实例的最上面一层添加了一层读写层(也就是容器层),这一层可以被使用容器的用户进行修改,进而影响整个镜像副本。
5.Docker 的仓库
5.1.常见镜像仓库分类
按是否对外开放分类:
(1)公有仓库:像阿里云、
Docker Hub等放在公有网络上的仓库,用户无需登录即可下载镜像,供大家访问和使用(2)私有仓库:不对外开放,通常位于私有网络,只有公司内部人员可以使用
按供应商和面向群体分类:
(1)Sponsor Registry(赞助):第三方提供的仓库,供客户和
Docker社区版用户使用(2)Mirror Registry(镜像):第三方提供的仓库,仅限注册用户使用,例如阿里云的镜像仓库需要注册才能访问
(3)Vendor Registry(供应商):由发布
Docker镜像的供应商提供的仓库,例如Google和Red Hat提供的镜像仓库服务(4)Private Registry(私有仓库):通过没有防火墙和额外安全层的私有实体提供的仓库,仅供内部使用
实际工作中,开发者一般都是先 pull 公共公有仓库和公司私有仓库中的镜像,进行开发,开发结束后再制作为镜像 push 到公司私有仓库中,然后反复交给不同团队 deploy(部署) 到 开发环境, 测试环境, 预发布环境, 生产环境 中,确保运行环境统一。
重要
补充:私有仓库部署工具有 Harbor, Nexus, Docker registry(已停止维护)... 您可以前往了解一下。
为了方便,我直接是哟个 Docker Hub 来存储镜像,这个网站类似 github,可以开放或私有镜像存储仓库。
5.2.使用官方公有镜像仓库
docker login [-u <用户> -p <密码>]登录镜像仓库(这里的用户和密码是指在Docker Hub上的注册的账号)docker logout登出镜像仓库(登出的默认也是Docker Hub中的账户)docker pull <镜像名称:镜像版本>/<镜像名称@>默认从Docker Hub拉取镜像文件,使用-a则拉取所有镜像,使用--disable-content-trust则忽略镜像的校验(默认开启)docker push默认从Docker Hub推送镜像文件,推送的过程中会发生压缩传输,并且不是简单把一个镜像文件直接传输上去,而是一个一个层传送上去,如果遇到远端仓库中已有某个镜像层,就会直接进行引用加快传输提高代码复用docker search查看当前远端存储库Docker Hub中已有公开的镜像文件
其中,如果是需要登录的镜像地址,就需要 到 Docker Hub 镜像仓库中创建一个账户,然后才可以开始实践有关登录的指令,如下开始进行账户注册。
注册好并且登录好账户后,我们开始使用指令。
# 尝试实践登录和登出指令
# 直接登录
$ docker login
Log in with your Docker ID or email address to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com/ to create one.
You can log in with your password or a Personal Access Token (PAT). Using a limited-scope PAT grants better security and is required for organizations using SSO. Learn more at https://docs.docker.com/go/access-tokens/
Username: limou3434
Password:
WARNING! Your password will be stored unencrypted in /home/ljp/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credential-stores
Login Succeeded
# 退出登录
$ docker logout
Removing login credentials for https://index.docker.io/v1/
# 使用参数一次性登录
$ docker login -u limou3434 -p ******
WARNING! Using --password via the CLI is insecure. Use --password-stdin.
WARNING! Your password will be stored unencrypted in /home/ljp/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credential-stores
Login Succeeded # 不过一般不建议使用这种带参数的# 尝试拉取镜像文件, 并查看当前已有镜像文件
# 使用版本号拉取镜像文件
$ sudo docker pull nginx:1.23.4
1.23.4: Pulling from library/nginx
f03b40093957: Pull complete
0972072e0e8a: Pull complete
a85095acb896: Pull complete
d24b987aa74e: Pull complete
6c1a86118ade: Pull complete
9989f7b33228: Pull complete
Digest: sha256:f5747a42e3adcb3168049d63278d7251d91185bb5111d2563d58729a5c9179b0
Status: Downloaded newer image for nginx:1.23.4
docker.io/library/nginx:1.23.4
# 使用字符串拉取镜像文件
$ sudo docker pull nginx@sha256:f5747a42e3adcb3168049d63278d7251d91185bb5111d2563d58729a5c9179b0 # 这串字符源于 dockerhub 的 tag 界面中, 下面有给出图解
docker.io/library/nginx@sha256:f5747a42e3adcb3168049d63278d7251d91185bb5111d2563d58729a5c9179b0: Pulling from library/nginx
Digest: sha256:f5747a42e3adcb3168049d63278d7251d91185bb5111d2563d58729a5c9179b0
Status: Image is up to date for nginx@sha256:f5747a42e3adcb3168049d63278d7251d91185bb5111d2563d58729a5c9179b0
docker.io/library/nginx@sha256:f5747a42e3adcb3168049d63278d7251d91185bb5111d2563d58729a5c9179b0
# 查看本地已有的镜像文件
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx 1.23.4 a7be6198544f 15 months ago 142MB
hello-world latest d2c94e258dcb 16 months ago 13.3kB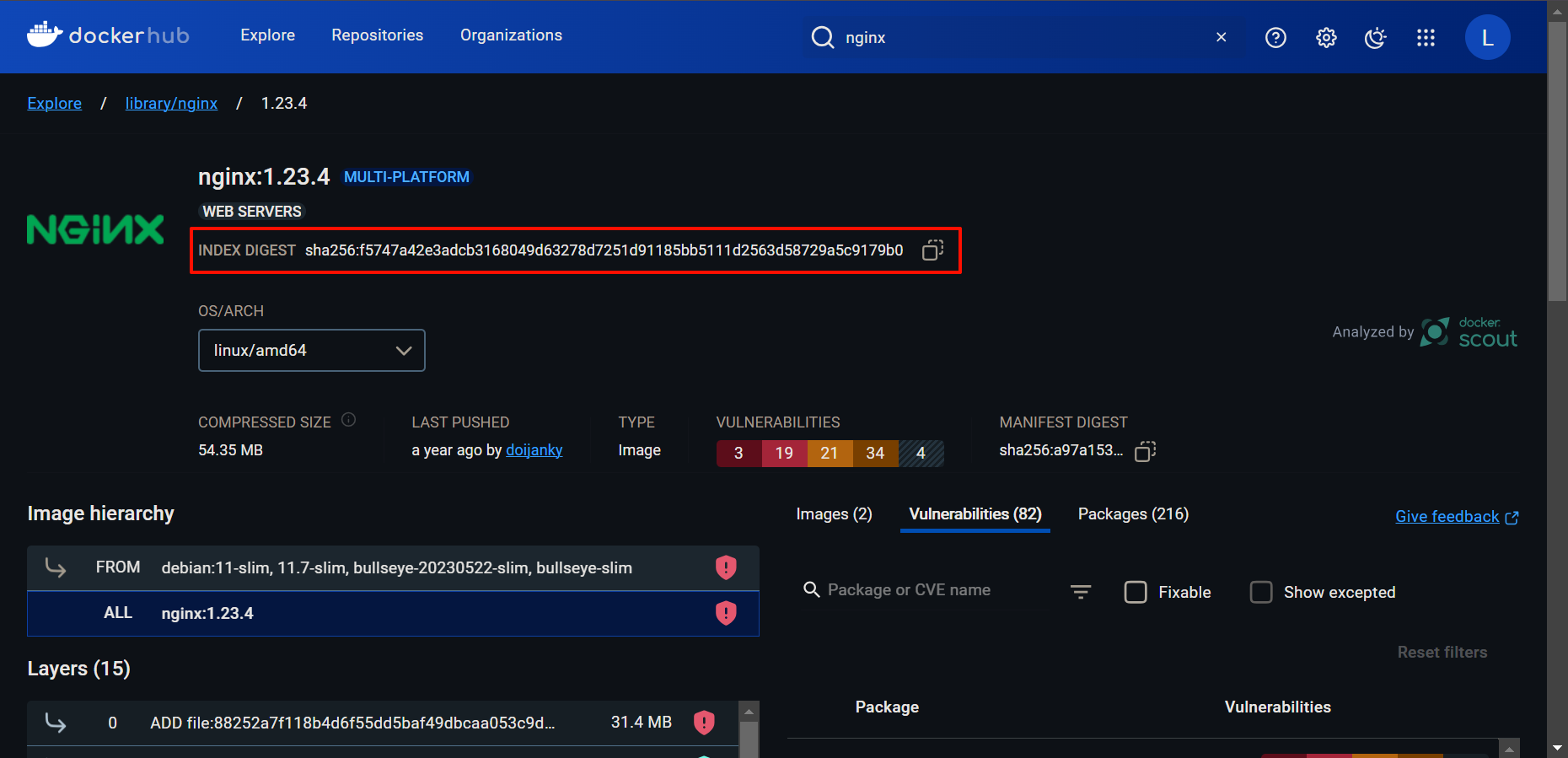
然后我们开始在 Docker Hub 上创建属于自己的镜像存储仓库,用来推送镜像文件。
注意
注意:存储仓库的名字必须和镜像文件名字相同。
而由于我们没有对 Nginx 镜像的推送权限,因此我们只能把自己的镜像 push 到自己的镜像存储库中,不过我们需要先有一个存储库,依照下图进行创建即可。
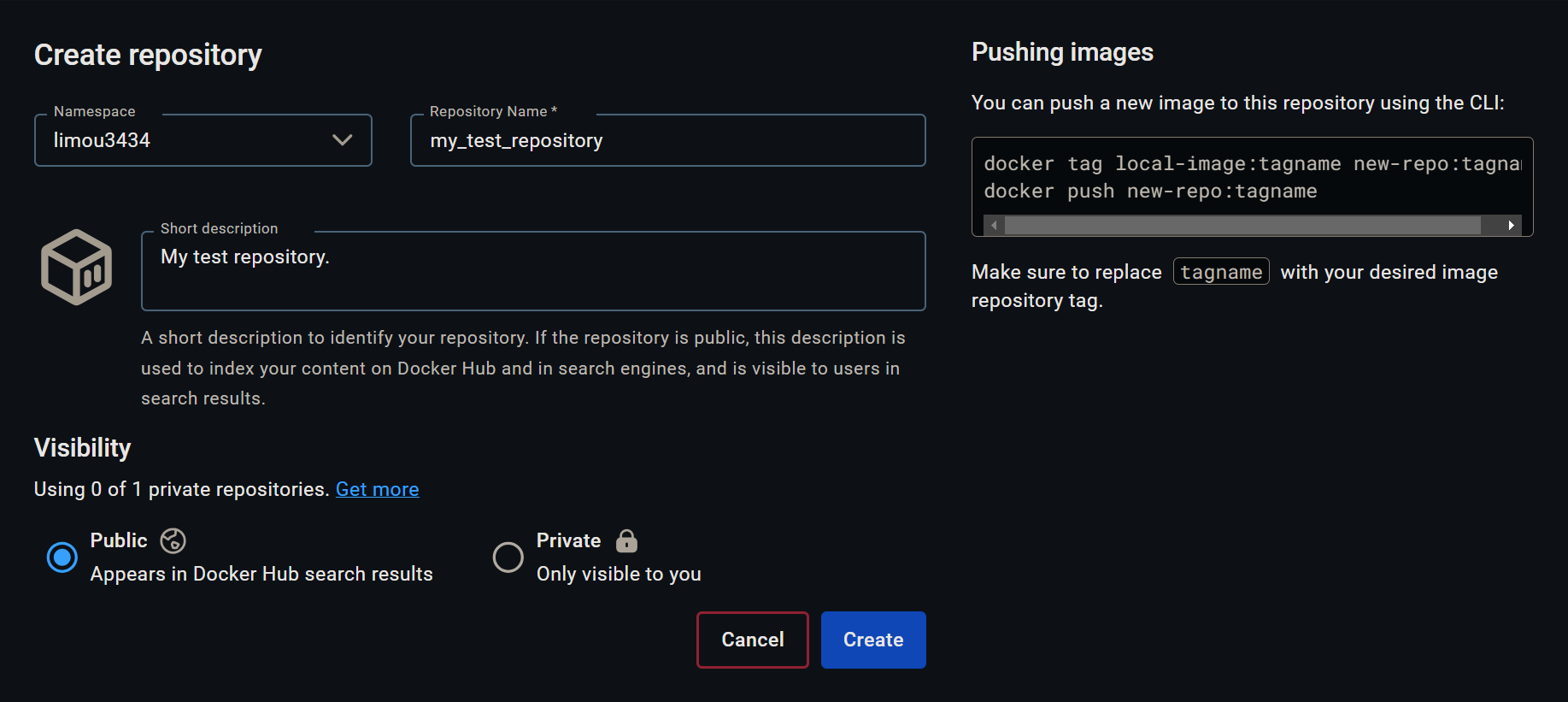
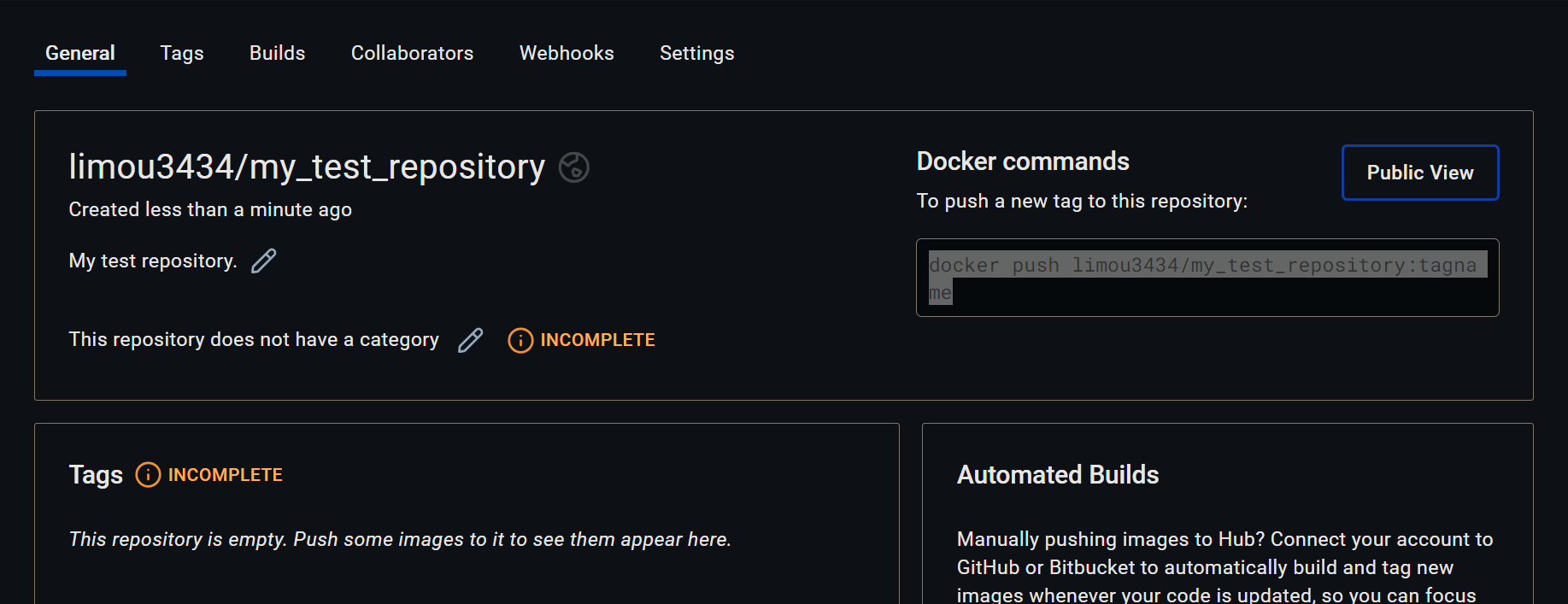
创建成功后就会跳出 docker push limou3434/my_test_repository:tagname (就不要用我的存储库了,我没多久就释放掉这个库了)然后在命令行中尝试执行这个命令。
# 推送单个镜像文件
# 查看当前已有的镜像文件
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx 1.23.4 a7be6198544f 15 months ago 142MB
hello-world latest d2c94e258dcb 16 months ago 13.3kB
# 需要给我们自己的镜像设置名称和标签
$ docker tag nginx:1.23.4 my_nginx:0.0.1
# 查看此时的镜像文件列表
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
my_nginx 0.0.1 a7be6198544f 15 months ago 142MB
nginx 1.23.4 a7be6198544f 15 months ago 142MB
hello-world latest d2c94e258dcb 16 months ago 13.3kB
# 不过这里的镜像文件名字必须和远端仓库一样, 没办法只好删除掉这个镜像文件重新设置了
$ docker rmi my_nginx:0.0.1
Untagged: my_nginx:0.0.1
$ docker tag nginx:1.23.4 limou3434/my_test_repository:0.0.1
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx 1.23.4 a7be6198544f 15 months ago 142MB
limou3434/my_test_repository 0.0.1 a7be6198544f 15 months ago 142MB
hello-world latest d2c94e258dcb 16 months ago 13.3k
# 然后开始做 push, 不过登陆之前建议重新登录一下 docker 账户, 否者有时会验证失败
$ docker login
Log in with your Docker ID or email address to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com/ to create one.
You can log in with your password or a Personal Access Token (PAT). Using a limited-scope PAT grants better security and is required for organizations using SSO. Learn more at https://docs.docker.com/go/access-tokens/
Username: limou3434
Password:
WARNING! Your password will be stored unencrypted in /root/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credential-stores
Login Succeeded
$ docker push limou3434/my_test_repository:0.0.1
The push refers to repository [docker.io/limou3434/my_test_repository]
4d33db9fdf22: Mounted from library/nginx
6791458b3942: Mounted from library/nginx
2731b5cfb616: Mounted from library/nginx
043198f57be0: Mounted from library/nginx
5dd6bfd241b4: Pushed
8cbe4b54fa88: Mounted from library/nginx
0.0.1: digest: sha256:a97a153152fcd6410bdf4fb64f5622ecf97a753f07dcc89dab14509d059736cf size: 1570 # 至此推送成功
 此时在这里就可以看到推送的记录,点进去也可以看到其他的详细信息,还可以一次性推送多个版本的同名镜像文件。
此时在这里就可以看到推送的记录,点进去也可以看到其他的详细信息,还可以一次性推送多个版本的同名镜像文件。
# 推送多个镜像文件
$ docker tag nginx:1.23.4 limou3434/my_test_repository:0.1.0
$ docker tag nginx:1.23.4 limou3434/my_test_repository:1.0.0
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx 1.23.4 a7be6198544f 15 months ago 142MB
limou3434/my_test_repository 0.0.1 a7be6198544f 15 months ago 142MB
limou3434/my_test_repository 0.1.0 a7be6198544f 15 months ago 142MB
limou3434/my_test_repository 1.0.0 a7be6198544f 15 months ago 142MB
hello-world latest d2c94e258dcb 16 months ago 13.3kB
$ docker push limou3434/my_test_repository -a
The push refers to repository [docker.io/limou3434/my_test_repository]
4d33db9fdf22: Pushed
6791458b3942: Layer already exists
2731b5cfb616: Pushed
043198f57be0: Layer already exists
5dd6bfd241b4: Layer already exists
8cbe4b54fa88: Layer already exists
0.0.1: digest: sha256:a97a153152fcd6410bdf4fb64f5622ecf97a753f07dcc89dab14509d059736cf size: 1570
4d33db9fdf22: Layer already exists
6791458b3942: Layer already exists
2731b5cfb616: Layer already exists
043198f57be0: Layer already exists
5dd6bfd241b4: Layer already exists
8cbe4b54fa88: Layer already exists
0.1.0: digest: sha256:a97a153152fcd6410bdf4fb64f5622ecf97a753f07dcc89dab14509d059736cf size: 1570
4d33db9fdf22: Layer already exists
6791458b3942: Layer already exists
2731b5cfb616: Layer already exists
043198f57be0: Layer already exists
5dd6bfd241b4: Layer already exists
8cbe4b54fa88: Layer already exists
1.0.0: digest: sha256:a97a153152fcd6410bdf4fb64f5622ecf97a753f07dcc89dab14509d059736cf size: 1570
既然有镜像仓库了,那能不能在命令行中查找 Docker Hub 上这个存储仓库呢?可以使用 images 和 search。
# 查找 Docker Hub 上存储仓库镜像内容
# 使用 images 指令
$ docker images limou3434/my_test_repository
REPOSITORY TAG IMAGE ID CREATED SIZE
limou3434/my_test_repository 0.0.1 a7be6198544f 15 months ago 142MB
limou3434/my_test_repository 0.1.0 a7be6198544f 15 months ago 142MB
limou3434/my_test_repository 1.0.0 a7be6198544f 15 months ago 142MB
# 使用 search 指令
$ docker search limou3434/my_test_repository:0.0.1 --no-trunc # --no-trunc 可以显示完整的镜像描述, 而不会因为信息较长发生截断
NAME DESCRIPTION STARS OFFICIAL
limou3434/my_test_repository My test repository. 0
# 不过 search 指令还能更加详细进行查询
$ docker search nginx --filter is-official=true # --filter 选项用于过滤搜索结果, is-official = true 只过滤出官方镜像
NAME DESCRIPTION STARS OFFICIAL
nginx Official build of Nginx. 20170 [OK]
$ docker search nginx --filter stars=20171 # stars 代表过滤大于 stars 值的仓库
NAME DESCRIPTION STARS OFFICIAL重要
补充:另外,也可以使用一些云服务厂商提供的服务,待补充...
5.3.使用个人私有镜像仓库
待补充...
6.Docker 的基础
6.1.更改软件配置
6.1.1.修改镜像加速地址
由于某些比较屮的原因,这里提供一个镜像源的更改方案,让镜像获取更加方便,我是参考 这篇文章 的。配置完毕后,可以运行以下代码进行测试。我的配置文件如下:
# 我的配置文件
$ cat /etc/docker/daemon.json
{
"registry-mirrors" :
[
"https://docker.m.daocloud.io",
"https://noohub.ru",
"https://huecker.io",
"https://dockerhub.timeweb.cloud",
"https://docker.mirrors.ustc.edu.cn",
"https://hub-mirror.c.163.com",
"https://mirror.ccs.tencentyun.com"
]
}# 测试配置是否成功
$ sudo docker run hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
c1ec31eb5944: Pull complete
Digest: sha256:53cc4d415d839c98be39331c948609b659ed725170ad2ca8eb36951288f81b75
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/注
吐槽:额...且用且珍惜叭,如果不行就配置下代理服务器叭...
镜像仓库网站的原理本身也不复杂,可以用如下图进行解释。
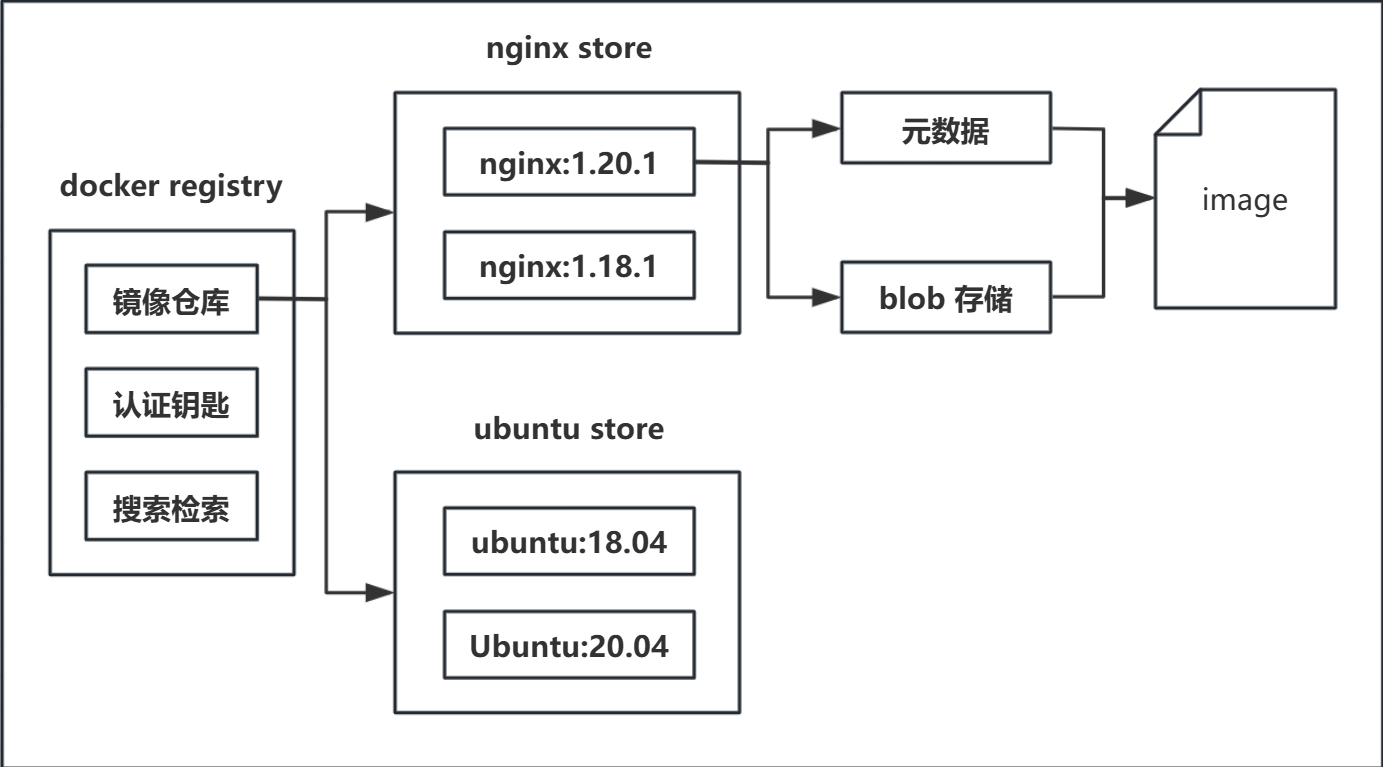
而有关的镜像,可以 在 dockerhub 上进行查找不同的镜像。
6.1.2.修改配置文件地址
待补充...
6.2.核心命令解析
核心指令这里只是一个快速阅览手册,实践这些指令的内容我大部分都写在文章的最后面。因此,您可以一边查看指令,一边阅读最低下的实践部分,并且打开自己的 Linux 进行实践。
6.2.1.镜像文件指令
docker image ls查看当前本地存储库已有的镜像文件-a把所有镜像包括中间映像层列出来,中间映像层通常是在某些镜像构建的过程中产生的,此时您可能会看到一些仓库名和版本号均为<none>的镜像,这些也叫做悬空镜像--digests显示镜像的摘要信息-q只显示镜像ID
docker image inspect <repository>:<tag>查看镜像摘要信息,也就是镜像的哈希标识信息,用于标识镜像的唯一性docker image history查看镜像的构建历史,提供每一层的详细信息,实际上pull指令就是把各个层给拉取下来, 然后在本地不断叠加层,最终形成一个完整的文件系统docker image rm <repository>:<tag>删除镜像文件docker image prune删除悬空镜像-a删除所有未被使用的镜像,而不仅仅是悬空镜像- 这个甚至可以设置定时删除,待补充...
docker image tag <old-repository>:<old-tag>/<existing-image-id> <new-repository>:<new-tag>修改镜像文件的名称和标签,类似git做一个标记docker image save <镜像名称:镜像版本> <镜像压缩包名.tar>将镜像文件保存为归档文件(完整地保存镜像的数据,包括镜像历史)docker image load -i <tar文件地址>将归档文件加载为镜像文件(save和load就有点像是压缩包压缩和解压的过程,很简单)docker image build [--build-arg 构建参数符=构建参数值] -f <dockfile文件目录> [--label version=标签] [--no-cache] [--pull] [--quiet] [--rm] [--tag 镜像名称:镜像版本] [--network 网络模式]通过dockerfile制作镜像文件(这个指令很重要,我们后面进行实践)--build-arg 构建参数符=构建参数值使用构建参数,例如--build-arg MY_VAR=value-f <dockfile文件目录>从自定义路径使用Dockerfile--label version=标签添加标签--no-cache禁用缓存以确保每层都重新构建--pull尝试从仓库中更新依赖的基础镜像--quiet使用安静模式输出--rm删除中间容器--tag 镜像名称:镜像版本设置镜像名称和镜像版本- 设置网络模式为,比如
host
重要
补充:有些指令解释起来比较麻烦,后面有篇幅比较大的实践时再来使用,这里简单试几个。
# 使用镜像文件指令
$ sudo docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
limou3434/my_test_repository 0.0.1 a7be6198544f 15 months ago 142MB
limou3434/my_test_repository 0.1.0 a7be6198544f 15 months ago 142MB
limou3434/my_test_repository 1.0.0 a7be6198544f 15 months ago 142MB
nginx 1.23.4 a7be6198544f 15 months ago 142MB
hello-world latest d2c94e258dcb 16 months ago 13.3kB
nginx 1.23.3 ac232364af84 17 months ago 142MB
$ sudo docker image ls --digests
REPOSITORY TAG DIGEST IMAGE ID CREATED SIZE
nginx 1.23.4 sha256:f5747a42e3adcb3168049d63278d7251d91185bb5111d2563d58729a5c9179b0 a7be6198544f 15 months ago 142MB
limou3434/my_test_repository 0.0.1 sha256:a97a153152fcd6410bdf4fb64f5622ecf97a753f07dcc89dab14509d059736cf a7be6198544f 15 months ago 142MB
limou3434/my_test_repository 0.1.0 sha256:a97a153152fcd6410bdf4fb64f5622ecf97a753f07dcc89dab14509d059736cf a7be6198544f 15 months ago 142MB
limou3434/my_test_repository 1.0.0 sha256:a97a153152fcd6410bdf4fb64f5622ecf97a753f07dcc89dab14509d059736cf a7be6198544f 15 months ago 142MB
hello-world latest sha256:53cc4d415d839c98be39331c948609b659ed725170ad2ca8eb36951288f81b75 d2c94e258dcb 16 months ago 13.3kB
nginx 1.23.3 sha256:f4e3b6489888647ce1834b601c6c06b9f8c03dee6e097e13ed3e28c01ea3ac8c ac232364af84 17 months ago 142MB
$ sudo docker image history nginx:1.23.4 # 该层已丢失或是中间层, 则会显示 <missing>
IMAGE CREATED CREATED BY SIZE COMMENT # 该层的注释
a7be6198544f 15 months ago /bin/sh -c #(nop) CMD ["nginx" "-g" " daemon… 0B
<missing> 15 months ago /bin/sh -c #(nop) STOPSIGNAL SIGQUIT 0B
<missing> 15 months ago /bin/sh -c #(nop) EXPOSE 80 0B
<missing> 15 months ago /bin/sh -c #(nop) ENTRYPOINT ["/docker-entr… 0B
<missing> 15 months ago /bin/sh -c #(nop) COPY file: e57eef017a414ca7… 4.62kB
<missing> 15 months ago /bin/sh -c #(nop) COPY file: abbcbf84dc17ee44… 1.27kB
<missing> 15 months ago /bin/sh -c #(nop) COPY file: 5c18272734349488… 2.12kB
<missing> 15 months ago /bin/sh -c #(nop) COPY file: 7b307b62e82255f0… 1.62kB
<missing> 15 months ago /bin/sh -c set -x && addgroup --system -… 61.6MB
<missing> 15 months ago /bin/sh -c #(nop) ENV PKG_RELEASE = 1~bullseye 0B
<missing> 15 months ago /bin/sh -c #(nop) ENV NJS_VERSION = 0.7.11 0B
<missing> 15 months ago /bin/sh -c #(nop) ENV NGINX_VERSION = 1.23.4 0B
<missing> 15 months ago /bin/sh -c #(nop) LABEL maintainer = NGINX Do… 0B
<missing> 15 months ago /bin/sh -c #(nop) CMD ["bash"] 0B
<missing> 15 months ago /bin/sh -c #(nop) ADD file: 88252a7f118b4d6f5… 80.5MB
# 尝试删除镜像失败
$ sudo docker image rm hello-world:latest
Error response from daemon: conflict: unable to remove repository reference "hello-world:latest" (must force) - container 28bd08f31582 is using its referenced image d2c94e258dcb
# 查找当前还在用该镜像的容器
$ sudo docker ps -a --filter ancestor=hello-world:latest
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
28bd08f31582 hello-world "/hello" 7 days ago Exited (0) 7 days ago fervent_austin
# 停止容器(后面学)
$ sudo docker stop 28bd08f31582
28bd08f31582
# 删除容器(后面学)
$ sudo docker rm 28bd08f31582
# 再次尝试删除镜像成功
$ sudo docker image rm hello-world:latest
Untagged: hello-world:latest
Untagged: hello-world@sha256:53cc4d415d839c98be39331c948609b659ed725170ad2ca8eb36951288f81b75
Deleted: sha256:d2c94e258dcb3c5ac2798d32e1249e42ef01cba4841c2234249495f87264ac5a
# 查看镜像是否已经被删除
$ sudo docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx 1.23.4 a7be6198544f 15 months ago 142MB
limou3434/my_test_repository 0.0.1 a7be6198544f 15 months ago 142MB
limou3434/my_test_repository 0.1.0 a7be6198544f 15 months ago 142MB
limou3434/my_test_repository 1.0.0 a7be6198544f 15 months ago 142MB
nginx6.2.2.镜像容器指令
docker container ls列出容器信息列表-a显示所有的容器,包括未运行的-f/--filter根据条件过滤显示的内容--format指定返回值的模板文件,如json或者table-l显示latest(最新)的容器-n列出最近创建的n个容器--no-trunc不截断输出容器详细信息-q静默模式,只显示容器编号-s显示总的文件大小
(初建|Created)docker container create创建容器后,不立即启动运行,容器进入初建状态(运行|Running)docker container start容器转为运行状态(初建+运行|Created+Running)docker container run [--oom-kill-disable] --name <容器名> [--rm] [-it] [-d] [-p <本地端口:容器端口>/-P] [-h <主机名>] [-v <本地目录:容器目录>] [-e 环境变量名="环境变量值"] [--cpuset-cpus="1,2,..."] [-m <数值k/b/m/g>] [--network <连接类型>] [--restart=...] <镜像名称:镜像版本> [<指令>]启动容器,注意这个指令是二合一的指令,一个容器不能重复使用run指令,因为容器已经被创建了,只能使用start使得容器转为运行状态--oom-kill-disable禁用OOM杀手(后面会提到这个事情)--name <容器名>指定容器名称--rm可以在容器退出时自动退出容器(并且容器也被销毁清理),适合做临时测试-it其中-i表示保持标准输入并且为容器分配一个类似本地操纵的伪终端,-t为容器重新分配一个为输入终端-d以后台模式启动容器,因此没有交互终端可以使用-p <本地端口:容器端口>/-P做端口映射,-P是做随机端口映射-h <主机名>指定容器的hostname-v <本地目录:容器目录>做目录映射, 两端共享目录(必须是绝对路径)下所有数据,挂载末尾还可以加:ro成为只读模式挂载(另外这个选项其实有三种模式,后面我会展开细说)-e 环境变量名="环境变量值"给容器内部设置环境变量--cpuset-cpus="1,2,..."限制只能使用处理器1和2等-m <数值k/b/m/g>限制内存大小,可以更换单位--memory-swap <数值k/b/m/g>设置总内存(物理内存 + 交换内存)限制,当物理内存不足时, 操作系统会把不常用的数据暂时存放到磁盘上的交换空间,以腾出RAM供其他需要更多内存的进程使用--network <连接类型>指定网络的连接类型[--restart=...]设置是否自动重启容器--restart=no [容器名]默认值不自动重启--restart=on-failure:<最多重启次数> [容器名]若容器的退出状态非0,则docker自动重启容器,可以指定重启次数,若超过指定次数未能启动容器则放弃重启--restart=always [容器名] :always容器退出时总是重启--restart=unless-stopped [容器名]容器退出时总是重启,但不考虑Docker守护进程启动时就已经停止的容器重要
补充:如果容器启动时没有设置
--restart参数,则通过下面命令进行更新docker update --restart=always <容器名><镜像名称:镜像版本>要启动的目标镜像文件<指令>这里会运行一个指令,填入bash就表示在容器内部启动一个bash程序
(开始暂停|Start Pause)docker container pause容器进入暂停状态,暂停的实质是剥夺CPU资源,因此容器内部的所有进程都会被暂停(取消暂停|End Pause)docker container unpause取消暂停状态,容器进入运行状态(退出|Exited)docker container stop <容器id>/<容器名称>[, ...]停止运行容器并且退出,完全关闭并且进行资源清理(但是容器本身还存在),如果超过过时间就会发送信号终止容器进程(退出|Exited)docker container kill容器在故障(死机)时,执行kill(断电),容器转入停止状态,这种操作容易丢失数据,除非必要,否则不建议使用(删除|Removing)docker container rm删除容器,容器转入删除状态,不过只能删除处于停止状态的容器(删除|Removing)docker container prune和上面指令类似,但是自动检测已经停止运行的容器docker container restart重启容器,容器转入运行状态docker container cp 宿主主机源路径 容器名:容器路径可以把一些放在宿主主机上的文件或目录拷贝到容器里。另外,这个指令也可以进行反方向的操作,也就是从容器主机拷贝到宿主主机中,有些情况下很方便docker container exec -it <容器名> <shell类型>有时需要启用后台模式中运行容器的shell终端,此时就需要启动shell,这个时候就可以使用-it来启动终端docker container attach <容器名>用于连接到一个已经在运行的容器的终端,可以查看容器输出并与容器进行交互。与docker exec不同的是,docker attach是直接连接到容器的主进程(这代表着可以直接看到主进程的标准输出和标准错误,但是一旦使用[ctrl+c]就会导致容器也跟着退出...挺危险的),而docker exec可以在容器内启动一个新的进程docker container logs [-f] [-n 行数] <容器名>可以查看容器输出的日志消息,尤其是标准输出和标准错误,加个-f就可以实时查看日志输出,否则日志输出就是静态的,-n只会显示出最新的指定行数的日志信息docker container port <容器名>可以查看容器的端口映射docker container rename <容器名>重命名容器的名称docker container update [一些新配置] <容器名>更新容器的资源配置--cpus指定容器可以使用的CPU核心数。例如--cpus="1.5"允许容器使用1.5个CPU核心--memory设置容器的最大内存限制。例如,--memory="500m"限制容器使用的内存不超过500MB--memory-swap设置容器的交换空间限制。例如,--memory-swap="1g"允许容器使用最多1GB的交换空间--cpu-shares调整容器的CPU共享权重,相对值用于CPU调度--oom-kill-disable禁用内存不足(OOM)杀死功能[--restart=...]前面有介绍过
docker container top <容器名> [ps参数]可以从宿主机器上查看容器内部的进程消息,并且支持ps命令参数docker container stats <容器名>显示容器资源的使用情况,包括CPU, 内存, 网络 I/O...但是时动态的,非常好用docker container inspect <容器名>查看容器详细信息,这个更加有用,可以看到一些Json信息,包含了非常详细的容器配置信息-f指定返回值的模板文件,如table, json-s显示总的文件大小
docker container diff <容器名>可以查看容器内部文件系统的变化(比如删除或新增了某些文件,通常A表示新增的文件或目录,D表示删除的文件或目录,C表示修改过的文件或目录docker container commit [-a <作者信息>] [-m <说明信息>] [-p] [-c <描述信息>] <容器名> 新镜像名称:新镜像版本命令将基于某个已存在的容器的当前状态创建一个新的镜像,可以把容器的当前文件系统和配置保存为一个新的Docker镜像。这个新镜像可以用来创建新的容器,继承了原容器的所有更改-a <作者信息>提交的镜像作者-m <说明信息>提交时的说明文字-p在commit时,将当前容器暂停-c <描述信息>使用Dockerfile指令来创建镜像,可以用来修改启动指令
docker container export <容器名> -o <容器快照名.tar>将容器导出为容器快照(只保留容器当前的状态,丢失所有元数据和历史记录)docker container import <容器快照地址> <镜像名称:镜像版本>将容器快照导入创建出新镜像文件(其实容器快照也可以使用docker load来导入...)docker container wait <容器名>适用于需要等待容器完成任务并获取其退出状态的场景,常用于脚本化流程中的同步操作docker container logs <容器名>可以查看容器日志,如果需要动态查看日志可以加上-f
重要
补充:有些指令解释起来比较麻烦,后面有篇幅比较大的实践时再来使用,这里简单试几个。
# 使用 run 启动容器后再 exit 就会使容器处于退出状态, 如果退出后手动使用 start 再退出就不会有这种行为
# 启动容器后直接退出
$ sudo docker run --name my_nginx -it -p 8086:80 nginx:1.23.3 bash
root@abb0cb095eaf:/# exit
exit
# 查看容器状态
$ sudo docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
abb0cb095eaf nginx:1.23.3 "/docker-entrypoint.…" 7 seconds ago Exited (0) 3 seconds ago my_nginx
# 重新使容器运行起来
$ sudo docker container start my_nginx
my_nginx
# 检查容器状态是否为运行状态
$ sudo docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
abb0cb095eaf nginx:1.23.3 "/docker-entrypoint.…" 46 seconds ago Up 7 seconds 0.0.0.0:8086->80/tcp, :::8086->80/tcp my_nginx
# 重写打开容器内部的模拟终端并且也直接退出
$ sudo docker container exec -it my_nginx bash
root@abb0cb095eaf:/# exit
exit
# 重新查看容器状态
$ sudo docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
abb0cb095eaf nginx:1.23.3 "/docker-entrypoint.…" About a minute ago Up 23 seconds 0.0.0.0:8086->80/tcp, :::8086->80/tcp my_nginx# 使用 attach 后再使用 [ctrl+c] 退出后容器也会一起退出, 除非使用 -d 启动容器
# >>> begin: bash1 >>>
$ sudo docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# 只有这个第一次启动的进程才会显示日志
$ sudo docker container run --name my_nginx -it -p 8086:80 nginx:1.23.3 bash
root@824adac62bde:/# nginx
2024/09/12 16:08:37 [notice] 13#13: using the "epoll" event method
2024/09/12 16:08:37 [notice] 13#13: nginx/1.23.3
2024/09/12 16:08:37 [notice] 13#13: built by gcc 10.2.1 20210110 (Debian 10.2.1-6)
2024/09/12 16:08:37 [notice] 13#13: OS: Linux 5.15.0-113-generic
2024/09/12 16:08:37 [notice] 13#13: getrlimit(RLIMIT_NOFILE): 1048576:1048576
root@824adac62bde:/# 2024/09/12 16:08:37 [notice] 14#14: start worker processes
2024/09/12 16:08:37 [notice] 14#14: start worker process 15
2024/09/12 16:08:37 [notice] 14#14: start worker process 16
root@824adac62bde:/# 210.21.79.236 - - [12/Sep/2024:16:08:50 +0000] "GET / HTTP/1.1" 200 615 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36" "-"
# <<< end <<<
# >>> bash2 begin >>>
# 这个终端是在没有浏览器访问前启动的, 无论前端浏览器怎么访问都无法在这里获取日志
$ sudo docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
824adac62bde nginx:1.23.3 "/docker-entrypoint.…" 50 seconds ago Up 50 seconds 0.0.0.0:8086->80/tcp, :::8086->80/tcp my_nginx
$ sudo docker container exec -it my_nginx bash
root@824adac62bde:/#
$ exit # 哪怕是退出了
$ sudo docker container ls -a # 可以看到容器也不会被退出
[sudo] password for ljp:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
824adac62bde nginx:1.23.3 "/docker-entrypoint.…" 19 minutes ago Up 19 minutes 0.0.0.0:8086->80/tcp, :::8086->80/tcp my_nginx
# <<< end <<<# 但是使用 attach 情况就不一样了
# >>> begin: bash1 >>>
# ... 忽略了之前的输出 ...
root@824adac62bde:/# ls # 这个 ls 不是 bash1 执行的, 而是 bash2 执行的时候同步过来的
bin dev docker-entrypoint.sh home lib64 mnt proc run srv tmp var
boot docker-entrypoint.d etc lib media opt root sbin sys usr
root@824adac62bde:/# 210.21.79.236 - - [12/Sep/2024:16:38:00 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36" "-"
exit
exit
# <<< end <<<
# >>> begin: bash2 >>>
$ sudo docker container attach my_nginx
root@824adac62bde:/# ls # 这个 ls 是 bash2 自己执行的
bin dev docker-entrypoint.sh home lib64 mnt proc run srv tmp var
boot docker-entrypoint.d etc lib media opt root sbin sys usr
# 可以看到上下两个 bash 在浏览器访问时, 就会两同步出现日志输出
root@824adac62bde:/# 210.21.79.236 - - [12/Sep/2024:16:38:00 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36" "-"
exit
exit
$ sudo docker container ls -a # 可以看到这个 bash2 执行了 exit, 导致 bash1 也会退出, 并且容器也退出了
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
824adac62bde nginx:1.23.3 "/docker-entrypoint.…" 37 minutes ago Exited (0) 7 seconds ago my_nginx
# <<< end <<<7.Docker 的错误
Docker 有两种比较常见的错误 killed by out-of-memory(内存溢出) 和 container process exitde(异常终止),出现后者这种状况则会进入 Should restart? 选择是否重启。
7.1.内存溢出
Docker 在处理 OOM 事件时分为三种情况。
7.1.1.超过内存限制
当容器中的应用程序使用的内存超过了主机系统分配给该容器的内存限制时,会触发 OOM 事件。此时容器会被强制关闭,但是关闭容器的不是 Docker Daemon(Docker守护进程),而是宿主机的操作系统。因为容器实际上是运行在宿主机操作系统上的一组进程。宿主机通过 cgroups(控制组) 对这些进程设定资源上限,当进程申请的资源达到上限时,宿主机内核会触发 OOM 事件并关闭相关进程。
7.1.2.禁用内存限制
如果用户不希望容器在内存耗尽时被关闭,可以使用 --oom-kill-disable 参数来禁用 OOM-Killer。此时如果使用 -m 参数设置了容器的内存上限,即便是容器达到内存资源上限,主机也不会立刻关闭容器,但也不会继续分配资源。此时容器将处于 hung(卡住) 状态,无法继续执行,陷入一种类似停滞的状态。
7.1.3.没有内存限制
如果用户使用了 --oom-kill-disable,但没有使用 -m 设置内存上限,容器将尽可能多地使用主机的内存资源。容器可以使用主机的所有可用内存,直到主机内存耗尽(这有可能会影响宿主主机的健康运行)。
7.2.异常终止
每个容器内部都有一个 Init 进程,其他所有进程都是其子进程。容器的运行依赖于 Init 进程。如果一个子进程因某种原因退出,Init 进程也会同步退出,最终导致整个容器关闭,因此 Docker 无法区分进程的退出是正常还是异常。
8.Docker 的拓展
在基于上述的学习中,您对 Docker 的使用和了解应该已经足够清晰了,但是还有一些值得补充的东西值得您学习...
8.1.Docker 的存储
存储卷 是一种在 Docker 容器和宿主机之间共享文件或目录的机制。它通过将宿主机上的一个目录与容器内的一个目录绑定起来实现。这样容器对这个目录的读写操作都会直接影响宿主机上的相应目录。这使得容器和宿主机可以共享数据(容器中的进程向这个目录写入数据时是直接写在宿主机的目录上的,这绕过了容器的文件系统,直接与宿主机的文件系统建立关联关系),数据在两者之间是同步的。
在有些时候,这种机制也可以达到保护数据的目的,例如容器虽然被销毁了,但是只要宿主机还在就不会出现数据丢失的问题。
而且不仅仅是容器主机和宿主主机进行共享,可以设置多个容器共享一个存储卷目录。
并且也有助于维护容器,数据的可持久化,保持容器的无状态属性(其实就是看有没有数据需要被持久化,没有就是无状态的),这使得容器是开箱即用而无需深度配置的装置。
而 Docker 镜像技术的基础是联合文件系统 UnionFS,这种文件系统的特点是允许将多个文件系统合并为一个虚拟的文件系统。这些文件系统可以在同一层次或不同层次,通过一个统一的视图提供给用户或程序。
但是问题是,这种文件系统的缺点也非常明显,删除和修改的效率比较低下,对于某些特殊应用来说(例如 Redis)就会显得不够使用。
因此 Docker 提供了三种方式来将数据从宿主机挂载到容器主机中。
8.1.1.默认挂载存储卷
Volume(默认存储卷) 是 Docker 管理的存储卷,默认存储在宿主机的 /var/lib/docker/volumes 目录下。创建存储卷后,用户使用 Volume 时,只需要在容器内指定挂载点(其实就是 run 的时候提供了 -v 选项,并且写成 -v 存储卷名:容器内部文件路径),Docker Daemon(Docker引擎) 会自动创建或使用一个已有的目录来建立卷与宿主机的关系。而有关存储卷的相关指令如下:
docker volume create [--driver/-d ...] [--label ...] <存储卷名>创建存储卷--driver/-d指定驱动,默认是local--label指定元数据
docker volume inspect [--format=<格式>]显示存储卷详细信息--format/-f可以指定相应的格式进行输出
docker volume ls [--format=<格式>] [--filter/-f 过滤条件]列出存储卷docker volume prune [--filter <过滤条件>] [--force/-f]清理所有无用数据卷--force/-f不提示是否删除
docker volume rm [--force/-f] <存储卷名> [, <存储卷名>, ...]删除卷,正在使用中存储卷无法直接删除--force/-f强制删除
# 使用默认存储卷 Volume
# 创建一个存储卷
$ sudo docker volume create my_volume
my_volume
# 查看存储卷是否创建成功
$ sudo docker volume ls
DRIVER VOLUME NAME
local my_volume
# 查看存储卷的位置
$ sudo ls /var/lib/docker/volumes
backingFsBlockDev metadata.db my_volume # 实际这个存储卷就是一个目录
# 查看存储器此时的内容
$ sudo docker volume inspect my_volume
[
{
"CreatedAt": "2024-09-16T12:19:03+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/my_volume/_data",
"Name": "my_volume",
"Options": null,
"Scope": "local"
}
]
$ sudo docker volume inspect --format=json my_volume
[{"CreatedAt":"2024-09-16T12:19:03+08:00","Driver":"local","Labels":null,"Mountpoint":"/var/lib/docker/volumes/my_volume/_data","Name":"my_volume","Options":null,"Scope":"local"}]
# 重新运行一个容器, 同时挂载一个存储卷
$ sudo docker container run --name my_nginx -it -p 8086:80 -v my_volume:/temp nginx:1.23.3 bash
# 在容器内部打开和宿主机挂载的文件
root@f67abaa2707e:/# cd /temp/
root@f67abaa2707e:/temp# ls
root@f67abaa2707e:/temp# apt-get update
Get:1 http://deb.debian.org/debian bullseye InRelease [116 kB]
Get:2 http://deb.debian.org/debian-security bullseye-security InRelease [27.2 kB]
Get:3 http://deb.debian.org/debian bullseye-updates InRelease [44.1 kB]
Get:4 http://deb.debian.org/debian bullseye/main amd64 Packages [8066 kB]
Get:5 http://deb.debian.org/debian-security bullseye-security/main amd64 Packages [294 kB]
Get:6 http://deb.debian.org/debian bullseye-updates/main amd64 Packages [18.8 kB]
Fetched 8566 kB in 8min 51s (16.1 kB/s)
Reading package lists... Done
# 在容器内部安装 vim 编辑器
root@f67abaa2707e:/temp# apt-get install vim
# 一大堆输出信息...
# 编辑并且查看文件是否已经保存完毕
root@f67abaa2707e:/temp# vim /temp/test.cpp
root@f67abaa2707e:/temp# cat /temp/test.cpp
int main() {
return 0;
}
# 退出容器查看宿主主机是否存在共享的文件
root@f67abaa2707e:/temp# exit
exit
$ sudo docker container ls -a
[sudo] password for ljp:
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f67abaa2707e nginx:1.23.3 "/docker-entrypoint.…" 18 minutes ago Exited (0) 12 seconds ago my_nginx
$ sudo tree /var/lib/docker/volumes/my_volume
/var/lib/docker/volumes/my_volume
└── _data
└── test.cpp
1 directory, 1 file
$ sudo cat /var/lib/docker/volumes/my_volume/_data/test.cpp
int main() {
return 0;
}不过,如果存在多个容器挂载同一个存储卷会怎么样呢?从下面现象可以看到这是完全可以的。
# 多个容器共享一个存储卷
# 观察此时的容器数量
$ sudo docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
f67abaa2707e nginx:1.23.3 "/docker-entrypoint.…" 24 minutes ago Exited (0) 6 minutes ago my_nginx
# 多运行一个容器, 并且挂载的存储卷和之前的容器是同一个
$ sudo docker container run --name my_another_nginx -it -p 8087:80 -v my_volume:/temp nginx:1.23.3 bash
# 查看是否存在上一个容器中写入的文件
root@7237fb621034:/# ls
bin docker-entrypoint.d home media proc sbin temp var
boot docker-entrypoint.sh lib mnt root srv tmp
dev etc lib64 opt run sys usr
root@7237fb621034:/# cd temp/
root@7237fb621034:/temp# ls
test.cpp
root@7237fb621034:/temp# cat test.cpp
int main() {
return 0;
}
# 编写新的文件
root@7237fb621034:/temp# echo "another_test.cpp" > another_test.cpp
root@7237fb621034:/temp# ls
another_test.cpp test.cpp
root@7237fb621034:/temp# exit
exit
# 查看是否成功写入到宿主主机中
$ sudo tree /var/lib/docker/volumes/my_volume
/var/lib/docker/volumes/my_volume
└── _data
├── another_test.cpp
└── test.cpp
1 directory, 2 files
# 查看此时两个容器的状态
$ sudo docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7237fb621034 nginx:1.23.3 "/docker-entrypoint.…" About a minute ago Exited (0) 2 seconds ago my_another_nginx
f67abaa2707e nginx:1.23.3 "/docker-entrypoint.…" 27 minutes ago Exited (0) 9 minutes ago my_nginx不过,既然存在共享,有一个令人担忧的问题,这个存储卷是否有数据一致性的保护?我们来检查一下。
# 检查是否有数据保护
# >>> begin: bash1 >>>
# 查看已有容器
$ sudo docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7237fb621034 nginx:1.23.3 "/docker-entrypoint.…" 38 minutes ago Exited (0) 36 minutes ago my_another_nginx
f67abaa2707e nginx:1.23.3 "/docker-entrypoint.…" About an hour ago Exited (0) 45 minutes ago my_nginx
# 编写一个循环脚本, 实时检查文件的内容
$ while true; do sudo cat /var/lib/docker/volumes/my_volume/_data/test.cpp; sleep 1; done
# ...
# <<< end <<<
# >>> begin: bash1 >>>
$ sudo docker container run --name my_nginx -it -p 8086:80 -v my_volume:/temp nginx:1.23.3 bash
$ apt-get update
$ apt-get install vim
$ vim /temp/test.cpp # 尝试同时进行编辑和保存
# <<< end <<<
# >>> begin: bash2 >>>
$ sudo docker container run --name my_another_nginx -it -p 8087:80 -v my_volume:/temp nginx:1.23.3 bash
$ apt-get update
$ apt-get install vim
$ vim /temp/test.cpp # 尝试同时进行编辑和保存
# <<< end <<<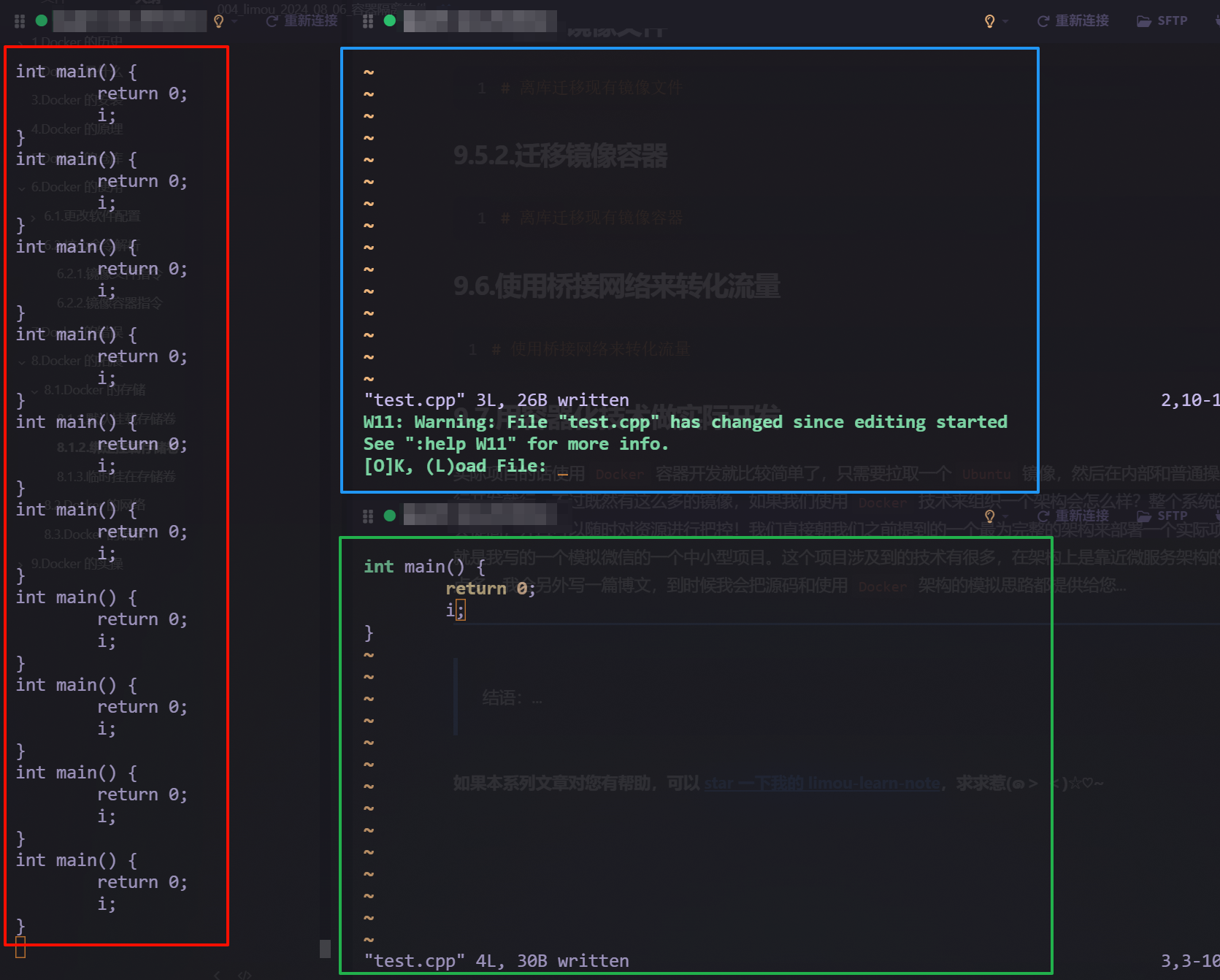
可以看到这个提示是 Vim 的一个警告信息,表示文件 test.cpp 在您开始编辑后发生了变化,这是由于另一个程序对该文件进行了修改。您此时有两个选择:
(O)继续当前编辑状态,不加载最新版本的文件(L)重新加载文件,将外部更改的内容应用到你的编辑窗口中
很遗憾 Docker 貌似无法保证存储卷的写入过程不是完全安全的(因为用户可以同时编辑一个文件,但是这种责任其实也不该交给 Docker),不过至少默认的数据同步还是有的,这部分我们后面会提到一些解决方案。
重要
补充:如果 -v 的选项中 : 的前面没有指定存储卷的名字,Docker 会使用默认的一串随机数字作为存储卷的名字。
重要
补充:这种默认存储卷挂载不会导致容器挂载点内的现有文件被覆盖。
8.1.2.绑定挂载存储卷
Bind Mount(绑定挂载存储卷) 允许用户将宿主机上的特定路径挂载到容器内。用户需要明确指定宿主机上的路径和容器内的路径(其实就是 -v 宿主主机路径:容器主机路径)。
# 绑定挂载存储卷
# 启动容器的同时绑定挂载存储卷
$ sudo docker container run --name bind_nginx -it -p 8088:80 -v /temp:/temp nginx:1.23.3 bash
# 在容器内部保存文件
root@81c081ab4cc5:/# echo "hello" >> /temp/t.txt
root@81c081ab4cc5:/# cat /temp/t.txt
hello
root@81c081ab4cc5:/# exit
exit
# 查看是否共享了文件
$ sudo cat /temp/t.txt
hello重要
补充:这种绑定存储卷挂载会导致容器挂载点内的现有文件被覆盖。
8.1.3.临时挂载存储卷
Tmpfs Mount(临时挂载存储卷) 还有一个之前没有提到过的选项,就是在 run 的时候加上选项 --mount type=挂载类型,target=容器主机内部挂载点,挂载类型指定了如何将宿主机的文件系统与容器的文件系统进行连接有一个最经典的挂载类型就是 tmpfs,这种类型将文件存储在内存中,通常会比较快,但数据也会在容器重启或停止时消散。
# 运行容器的同时使用临时挂载存储卷
$ sudo docker container run --name temp_nginx -it -p 8088:80 --mount type=tmpfs,target=/temp nginx:1.23.3 bash
# 尝试存储文件
root@08cf5f2e75a7:/# echo "temp" >> /temp/temp.txt
root@08cf5f2e75a7:/# cat /temp/temp.txt
temp
root@08cf5f2e75a7:/# exit
exit
# 可以发现没有任何明显的存储卷出现在默认的路径上
$ sudo ls -al /var/lib/docker/volumes/
total 36
drwx-----x 3 root root 4096 Sep 18 23:55 .
drwx--x--- 12 root root 4096 Sep 5 10:27 ..
brw------- 1 root root 252, 3 Sep 5 10:27 backingFsBlockDev
-rw------- 1 root root 32768 Sep 18 23:42 metadata.db
drwx-----x 3 root root 4096 Sep 16 12:19 my_volume
# 重新启动容器
$ sudo docker container start temp_nginx
temp_nginx
# 重新进入容器的内部查看文件是否存在
$ sudo docker container exec -it temp_nginx bash
root@08cf5f2e75a7:/# cat /temp/temp.txt
cat: /temp/temp.txt: No such file or directory # 果然找不到这个文件了, 这个文件是内存级别的文件, 现在已经被销毁了
root@08cf5f2e75a7:/# cd temp/
root@08cf5f2e75a7:/temp# ls
# 没有任何输出重要
补充:这种临时存储卷挂载会导致容器挂载点内的现有文件被覆盖。
重要
补充:除了使用 -v 其实还可以使用 --mount <key=value> [, <key=value>, ...],这个参数语义会更加明确一些,常见的 key 有下面的几个
type指定挂载的类型,可以是volume | bind | tmpfs也就是对应我们上面提到的三种source指定挂载源的位置- 对于
volume类型,源是存储卷的名称 - 对于
bind类型,源路径是宿主主机上的目录或文件
- 对于
target目标路径,也就是容器内对应的挂载点readonly | ro指定挂载为只读模式,容器内无法修改这个挂载点的数据(这种可以作为解决Docker无法保证数据安全的方案,即只使用一个容器进行修改,其他容器进行读取),并且只需要设置这个kye值即可,value是不需要设置的consistency关键字允许指定挂载的数据一致性级别,有助于优化不同挂载类型的数据读写行为,它通常有以下几种value值可以指定consistent(默认)可以确保读写操作的一致性。所有文件读写操作都经过同步,保证读到的是最新的数据适合需要确保数据一致性和同步的应用,比如数据库系统或需要高一致性的应用
cached优化文件访问性能,减少延迟。数据可能会被缓存,因此读操作可能会读到旧的数据,直到缓存更新适合读多写少的场景,比如静态文件服务,能够容忍短时间内的数据不一致
delegated优化写操作性能,写入操作可能会延迟到背景(其实就是后台的一种说法)中进行,不一定会立刻同步到宿主机上的最新数据,而是先把写入的数据缓存起来。这样读取操作可能读取到旧的未修改数据适合写操作频繁但读操作较少的场景,例如日志文件或临时数据
tmpfs-size选项用于指定内存文件系统的最大容量,只对tmpfs类型的存储卷有效tmpfs-mode使用与Unix/Linux文件权限相同的模式表示法来设置文件权限,只对tmpfs类型的存储卷有效
您可以自己尝试一下,和我们前面的结果大差不差...
8.2.Docker 的网络
这个也是非常重要的拓展之一,我们需要考虑的问题很多:
- 多个容器之间是如何通信的?
- 容器和宿主机是如何通信的?
- 容器和外界主机是如何通信的?
- 容器内的网络怎么样才能和其他容器进行隔离?
- 容器根本不需要网络的时候应该如何做?
- 容器需要更高的定制化网络该怎么办?
警告
警告:下文提到的网桥、网卡是同一个东西。
8.2.1.容器网络模型
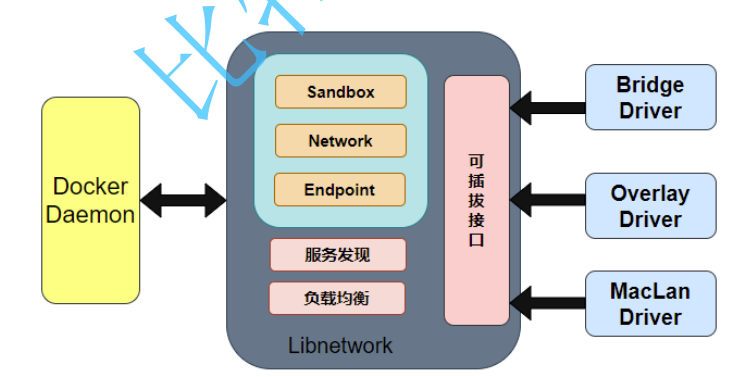
因此这方面 Docker 做足了功夫,CNM(Container Network Model, 容器网络模型) 规定对应的解决方案及架构需要依赖三个部分:
- Sandbox 提供了容器的虚拟网络栈,即端口、套接字、
IP路由表、防火墙、DNS配置等内容。用于隔离容器网络与宿主机网络,形成了完全独立的容器网络环境。 - Network
Docker内部的虚拟子网,使得网络内的参与者能够进行通讯。 - Endpoint 就是虚拟网络的接口,就像普通网络接口一样,
Endpoint的主要职责 是负责创建连接。Endpoint类似于常见的网络适配器,那也就意味着一个Endpoint只能接入某一个网络, 当容器需要接入到多个网络,就需要多个Endpoint。
而开源库 Libnetwork 是 CNM 的一个标准实现,该库本身采用 Go 语言编写,并且是跨平台的,也是 Docker 所使用的库,Docker 网络架构的核心代码都在这个库中。 Libnetwork 除了实现了 CNM 中定义的全部三个核心组件,还实现了本地服务发现、基于 Ingress 的容器负载均衡,以及网络控制层和管理层...功能。
8.2.2.容器网络驱动
Docker 内置了若干驱动,通常被称作原生驱动或者本地驱动。例如 Bridge Driver, Host Driver, Overlay Driver, MacVLan Driver, IPVLan Driver, None Driver...。每个驱动负责创建其上所有网络资源的创建和管理,详细信息可以 查看官方文档对网络驱动的解释。
驱动主要负责实现数据层相关内容,网络的连通性和隔离性等都是由驱动来处理的。驱动通过实现特定网络类型的方式扩展了 Docker 网络栈,例如桥接网络和覆盖网络。
而这些驱动通过可插拔的接口来支持不同的容器网络模型。
8.2.3.容器网络类型
Bridge 网络
- 描述:
bridge驱动会在Docker主机上创建一个Linux网桥。默认情况下,连接到同一网桥的容器可以相互通信 - 应用场景:当多个容器需要在同一台
Docker主机上通信时使用。是Docker容器的默认网络模式。 - 特点:容器与宿主机隔离,容器间可以使用同一个虚拟网桥进行通信
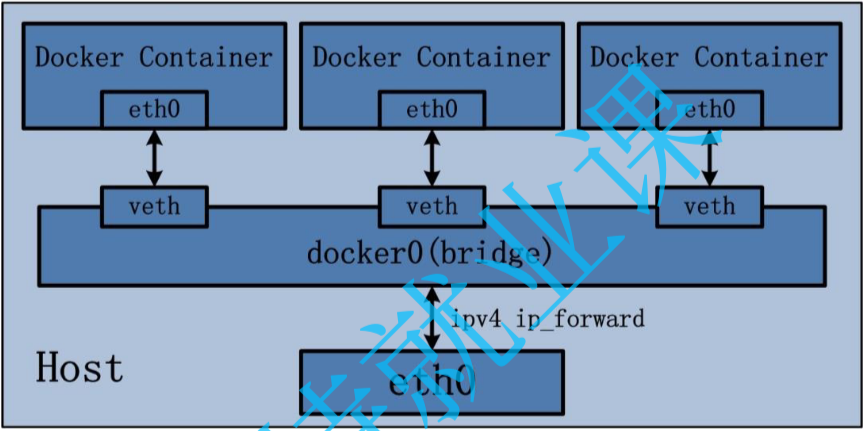
image-20240920190050185 - 描述:
Host 网络
- 描述:容器与
Docker主机之间没有网络隔离,容器直接使用主机的网络栈(原理其实就是和宿主主机使用同一个网络命名空间) - 应用场景:当容器需要直接使用主机网络,避免
NAT和额外的网络层时使用,通常用于高性能需求场景,但是有可能导致宿主主机网络资源耗尽 - 特点:网络与宿主机共享,但其他资源如文件系统、进程等仍被隔离
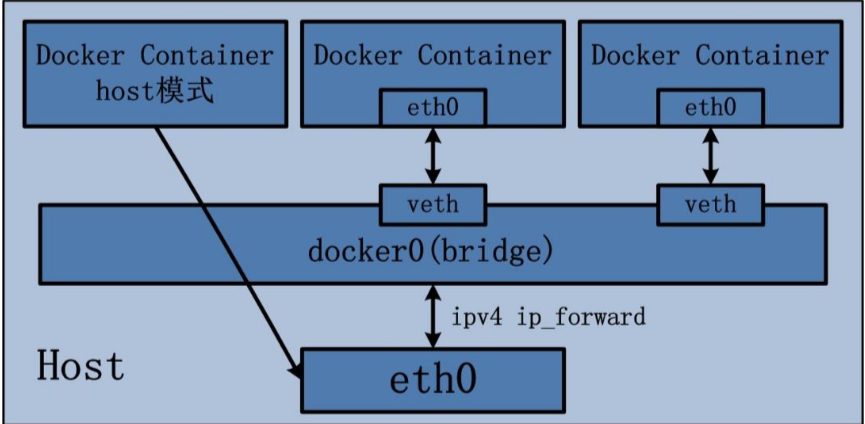
image-20240920190141005 - 描述:容器与
Container 网络
- 描述:新创建的容器与指定的现有容器共享同一个网络。它们共享
IP地址和端口等网络资源 - 应用场景:当两个容器需要共享相同的网络环境时使用,但文件系统和进程仍然独立
- 特点:两个容器通过
lo回环设备通信,共享网络资源但其他资源隔离,但是会导致容器之间产生依赖性,如果启动顺序不正确就会导致部分涉及到网络的容器无法启动
image-20240920190211931 - 描述:新创建的容器与指定的现有容器共享同一个网络。它们共享
None 网络(真空网络环境)
- 描述:
Docker容器拥有自己的网络命名空间,但不进行任何网络配置,容器没有网络功能(除了本地环回)。 - 应用场景:需要完全隔离的容器时使用,尤其是对网络安全有严格要求的场景
- 特点:容器无网卡、无
IP、无路由,完全网络隔离
- 描述:
Overlay 网络(远程宿主主机通信)
- 描述:用于跨多台
Docker主机的容器通信,适用于Docker Swarm集群中,将多个Docker守护进程连接在一起 - 应用场景:当需要多个
Docker主机上的容器协同工作时使用,如分布式集群服务 - 特点:跨主机的容器通信,集群内的服务可以相互通信
- 描述:用于跨多台
重要
补充:另外 Docker 安装后会默认创建一个网络接口 docker0(可以使用 ifconfig 查看网卡),它是一个网桥设备,允许 Docker 容器和宿主机之间进行通信,默认用于桥接网络中的容器。
# 查看默认网络接口 docker0, 查询结果为 172.17.0.1, 可看作 Docker 默认网络模式中的路由器
$ ifconfig
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
# 上面这一行就是本网卡携带的网络 IP 地址, 后面是掩码和广播地址
inet6 fe80::42:a4ff:fed5:52f7 prefixlen 64 scopeid 0x20<link>
ether 02:42:a4:d5:52:f7 txqueuelen 0 (Ethernet)
RX packets 62648 bytes 3674514 (3.6 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 92966 bytes 114284565 (114.2 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 08.2.4.容器网络指令
docker network create [--driver/-d <网络驱动类型>] [--gateway=<网关地址Gateway>] [--subnet=<网络子网IPAddress(携带子网掩码IPPrefixLen)>] [--ipv6] <网络名称>创建自定义Docker网络(可以理解为创建了一张虚拟网卡)docker network rm [-f]删除一个或多个Docker网络,-f是指强制删除docker network ls [--filter <过滤条件>] [--format <指定输出格式>] [--no-trunc] [--quiet/-q]列出所有的网络,这里的-q表示仅显示网络的ID即可(容器网络除了有自己的网络名字还有网络ID)docker network inspect <网络名称> [--format/-f <输出格式>]查看指定网络的详细信息docker network connect <网络名称> <容器名称> [--ip <指定容器的IPv4地址>] [--ip6 指定容器IPv6地址]将容器连接到网络docker network disconnect <网络名称> <容器名称> [-f]断开容器与网络的连接,-f就是强制断开的意思docker network prune [--force/-f]删除未使用的Docker网络,这里的-f是去除删除提示直接删除
重要
补充:启动时将容器连接到网络也是可以做到的。
docker run -itd --network=multi-host-network busybox-container稍微使用一下指令,并且验证一些事情就行,关于五种网络模式的实践,我们后面进行实操。
初步使用指令, 并且验证一些现象
# 查询默认网卡
$ ifconfig
docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.17.0.1 netmask 255.255.0.0 broadcast 172.17.255.255
inet6 fe80::42:a4ff:fed5:52f7 prefixlen 64 scopeid 0x20<link>
ether 02:42:a4:d5:52:f7 txqueuelen 0 (Ethernet)
RX packets 62648 bytes 3674514 (3.6 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 92966 bytes 114284565 (114.2 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# 请记下 172.17.0.1 这个网关地址, 后面有用
# 查询 docker 创建的网络(都可以理解为虚拟网卡)
$ sudo docker network ls
NETWORK ID NAME DRIVER SCOPE
d76247a506b9 bridge bridge local
641718df1c49 host host local
a65bf697fc48 none null local
# 查询 bridge 这张网卡的详细信息
$ sudo docker network inspect bridge
[
{
"Name": "bridge",
"Id": "d76247a506b9ed3e0b4f2865b438744436172e06e94f249804d26da2b7cdf273",
"Created": "2024-09-05T10:27:51.728180128+08:00",
"Scope": "local",
"Driver": "bridge", # 默认指定的 Docker 容器网络类型就是 bridge
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": null,
"Config": [
{
"Subnet": "172.17.0.0/16", # 虚拟网卡(虚拟路由器)可以利用这个掩码规则组件属于自己的局域网络
"Gateway": "172.17.0.1" # 可以看到这里和上面使用 Linux 命令行查询的地址是一样的, 这里其实配置的就是这个虚拟网卡所携带的地址, 也就是一个虚拟路由器所携带的地址, 因此和命令行在这里是同步的
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {
"a1e9275aac164a249f62e90fa2a82fe54a9d33d1762574d2866f350d0f665ce1": {
"Name": "test_nginx",
"EndpointID": "8e1665f75ab26ad4e37789e8f848dcd0b3a3aa13972655400ad146326a152ae1",
"MacAddress": "02:42:ac:11:00:02",
"IPv4Address": "172.17.0.2/16",
"IPv6Address": ""
}
},
"Options": {
"com.docker.network.bridge.default_bridge": "true",
"com.docker.network.bridge.enable_icc": "true",
"com.docker.network.bridge.enable_ip_masquerade": "true",
"com.docker.network.bridge.host_binding_ipv4": "0.0.0.0",
"com.docker.network.bridge.name": "docker0",
"com.docker.network.driver.mtu": "1500"
},
"Labels": {}
}
]
# 拉取镜像文件
$ sudo docker pull nginx:1.23.3
1.23.3: Pulling from library/nginx
f1f26f570256: Already exists
84181e80d10e: Already exists
1ff0f94a8007: Already exists
d776269cad10: Already exists
e9427fcfa864: Already exists
d4ceccbfc269: Already exists
Digest: sha256:f4e3b6489888647ce1834b601c6c06b9f8c03dee6e097e13ed3e28c01ea3ac8c
Status: Downloaded newer image for nginx:1.23.3
docker.io/library/nginx:1.23.3
# 查看镜像是否被成功拉取
$ sudo docker image ls -a
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx 1.23.3 ac232364af84 18 months ago 142MB
# 后台启动容器
$ sudo docker container run --name test_nginx -it -d -p 8088:80 nginx:1.23.3
a1e9275aac164a249f62e90fa2a82fe54a9d33d1762574d2866f350d0f665ce1
# 查看容器的详细信息
$ sudo docker container inspect test_nginx
"NetworkSettings": { # ... 我们这里只看网络设置 ...
"Bridge": "",
"SandboxID": "3f5ec294b0995857c1e5fec1e3b2dc37a1e52fc10bbd566c7d211468a50dc76c",
"SandboxKey": "/var/run/docker/netns/3f5ec294b099",
"Ports": { # 这里规定了宿主主机到容器主机的端口映射
"80/tcp": [
{
"HostIp": "0.0.0.0",
"HostPort": "8088"
},
{
"HostIp": "::",
"HostPort": "8088"
}
]
},
"HairpinMode": false,
"LinkLocalIPv6Address": "",
"LinkLocalIPv6PrefixLen": 0,
"SecondaryIPAddresses": null,
"SecondaryIPv6Addresses": null,
"EndpointID": "8e1665f75ab26ad4e37789e8f848dcd0b3a3aa13972655400ad146326a152ae1",
"Gateway": "172.17.0.1", # 容器网络的网关地址, 可以看到就是 Docker 为我们创建的虚拟网卡所携带的 ip 地址, 因此我们成功验证容器的默认网路是
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"IPAddress": "172.17.0.2",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"MacAddress": "02:42:ac:11:00:02",
"Networks": {
"bridge": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"MacAddress": "02:42:ac:11:00:02",
"DriverOpts": null,
"NetworkID": "d76247a506b9ed3e0b4f2865b438744436172e06e94f249804d26da2b7cdf273",
"EndpointID": "8e1665f75ab26ad4e37789e8f848dcd0b3a3aa13972655400ad146326a152ae1",
"Gateway": "172.17.0.1",
"IPAddress": "172.17.0.2",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"DNSNames": null
}
}
}
# 尝试使用 Docker 自己创建一个虚拟网卡
$ sudo docker network create --driver bridge --gateway=172.18.0.1 --subnet=172.18.0.0/16 test_network
b94066dba3c89ed9393042c13baa698a4a03cd063f3e5a3975288411b4f3a1cc
# 验证是否创建成功
$ sudo docker network ls
NETWORK ID NAME DRIVER SCOPE
d76247a506b9 bridge bridge local
641718df1c49 host host local
a65bf697fc48 none null local
b94066dba3c8 test_network bridge local
# 启动容器的同时接入网络
$ sudo docker container run --name another_test_nginx --network test_network -it -d -p 8087:80 nginx:1.23.3
fd4636b2864b3d1a90ab57cff60dd89b383f6edd84f445019f77a7baf0e9df2d
# 查看容器的详细信息
$ sudo docker container inspect another_test_nginx
"NetworkSettings": {
"Bridge": "",
"SandboxID": "aabeb6d278b501eb3158394a1ab57fa6998c51cff008331853bfbeb1f0107353",
"SandboxKey": "/var/run/docker/netns/aabeb6d278b5",
"Ports": {
"80/tcp": [
{
"HostIp": "0.0.0.0",
"HostPort": "8087"
},
{
"HostIp": "::",
"HostPort": "8087"
}
]
},
"HairpinMode": false,
"LinkLocalIPv6Address": "",
"LinkLocalIPv6PrefixLen": 0,
"SecondaryIPAddresses": null,
"SecondaryIPv6Addresses": null,
"EndpointID": "",
"Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"IPAddress": "",
"IPPrefixLen": 0,
"IPv6Gateway": "",
"MacAddress": "",
"Networks": {
"test_network": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"MacAddress": "02:42:ac:12:00:02",
"DriverOpts": null,
"NetworkID": "b94066dba3c89ed9393042c13baa698a4a03cd063f3e5a3975288411b4f3a1cc",
"EndpointID": "14335f8c2be3b9f8f594712b77ecfa342c52f205c2ad84c2e2adec91ef32cc16",
"Gateway": "172.18.0.1", # 172.18.0.1 是网关地址, 被路由器所占用
"IPAddress": "172.18.0.2", # 因此根据子网掩码, 自动分配一个子网地址给本容器
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"DNSNames": [
"another_test_nginx",
"fd4636b2864b"
]
}
}
}8.3.Docker 的编写
这里的编写是指元素编写一个独属于自己的镜像文件,其实这个过程就是编写 Dockerfile 配置文件,编写好后就可以交给 docker 工具进行镜像构建,这个其实只需要 查看官方文档学习 就可以了,我会在后面需要的地方进行实践。后续如果要系统整理的话再来,待补充...
8.4.Docker 的编排
为什么需要学习编排技术?因为我们之前学习的有关容器的内容,基本都是单单对一个具体容器的操作,我们未来会接触到更多的容器,一个一个管理未免也太繁琐了,这个时候就需要一个对容器们进行一个管理,也就是所谓的容器编排工具。
重要
补充:例如我们前面提到关于存储卷的问题,一旦存储卷和容器多了起来就不好管理了(例如启动参数未知、无法简单进行跨主机使用、运维场景复杂多变等)...
这里我只介绍单机容器管理工具 Docker Compose 这是官方的编排工具,可以查看 Docker Compose 官方文档 进行学习。
官方文档也有提及,Docker Compose 在传统上是面向开发环境和测试环境的,它并不适合作为生产环境使用(这方面 k8s 更加擅长)。
您可以使用 sudo apt-get install docker-compose 进行安装。
Docker Compose 使用 json 的超集 yaml 来在单机上进行配置 compose.yaml,然后通过 Compose CLI 也就是命令行工具来从配置中创建并且启动所有容器(服务)。
而 CLI 工具也很容易使用,和 Docker CLI 也有些类似:
docker compose up [--bulid] [--watch] [-d]启动您在compose.yaml文件中定义的所有服务(使用--bulid可以重新构建镜像文件并且启动对应的容器;--watch会自动监视项目中的文件变化,并在检测到变化时重新构建或重启相关的服务;-d表示分离可以在后台运行本指令对应的服务)docker compose stop暂停服务docker compose start启动服务docker compose restart重启服务docker compose down要暂停并移除正在运行的服务docker compose logs [service_name]查看容器的输出日志,用service_name可指定不同容器避免日志混乱docker compose ps列出所有服务及其当前状态- 如果
.yml配置文件是自定义的名字,则需要在每个compose指令加个-f <yml_config_path>参数指定配置文件的实际路径 docker compose ls如果已经有启动完毕的项目,就会被列出来,默认项目的名称就是配置文件所在的父目录
同样,实践部分的内容我放在了后面。
重要
补充:如果新增加编排配置文件的内容并希望加载新配置,而不影响已存在的容器和镜像,可以使用以下命令来实现。
- 使用
docker-compose up更新配置,这个命令会尝试重新创建、更新服务的容器,但不会影响已存在的镜像,除非您显式地更新了镜像版本。它会根据compose.yaml文件中的配置,检查现有容器是否需要更新。如果您没有修改镜像(例如没有修改image或build字段),Docker会尝试重新启动并应用新的配置,而不会重新拉取镜像,也不会删除任何镜像。 - 使用
docker-compose up --no-deps <server_name>只重启某个服务,这会更新work-gitea-server服务,而不会影响它所依赖的服务。 - 如果你只是想重启服务,而没有修改任何配置,可以使用
docker-compose restart。这将会重启所有服务的容器,不会影响镜像和原有数据。
9.Docker 的实操
9.1.使用别人制作的镜像文件
# 使用别人制作的镜像文件
# 下载镜像文件
sudo docker pull nginx:1.23.3
# 查看镜像文件
$ sudo docker images ls
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx 1.23.4 a7be6198544f 15 months ago 142MB
limou3434/my_test_repository 0.0.1 a7be6198544f 15 months ago 142MB
limou3434/my_test_repository 0.1.0 a7be6198544f 15 months ago 142MB
limou3434/my_test_repository 1.0.0 a7be6198544f 15 months ago 142MB
hello-world latest d2c94e258dcb 16 months ago 13.3kB
nginx 1.23.3 ac232364af84 17 months ago 142MB
# 检查端口合法
$ sudo lsof -i :8086 # 没有任何输出就是没有任何服务占用该端口
# 运行镜像文件
$ sudo docker run --name my_nginx --rm -it -p 8086:80 nginx:1.23.3 bash # 注意这里的 --rm
# 唤出了类似本地终端的交互提示符, 后面的字符串 7a86d1b1da47 代表容器编号, 可以使用这个 bash 简单看下操作系统版本
root@7a86d1b1da47:/# cat /etc/*release*
PRETTY_NAME="Debian GNU/Linux 11 (bullseye)"
NAME="Debian GNU/Linux"
VERSION_ID="11"
VERSION="11 (bullseye)"
VERSION_CODENAME=bullseye
ID=debian
HOME_URL="https://www.debian.org/"
SUPPORT_URL="https://www.debian.org/support"
BUG_REPORT_URL="https://bugs.debian.org/"
# 不过我们就不做配置文件了, 因为这个环境几乎没有一个常用编辑器(您也可以考虑使用 apt-get update 进行更新后再下载下面这些文本编辑工具)
root@7a86d1b1da47:/etc/nginx/conf.d# ls
default.conf
root@7a86d1b1da47:/etc/nginx/conf.d# nano test.conf
bash: nano: command not found
root@7a86d1b1da47:/etc/nginx/conf.d# vim test.conf
bash: vim: command not found
root@7a86d1b1da47:/etc/nginx/conf.d# vi test.conf
bash: vi: command not found
# 直接启动 Nginx(用 Nginx 的原生指令, 而不使用 systemd, 因为我们没有下载...)
root@7a86d1b1da47:/etc/nginx/conf.d# nginx
2024/09/07 16:33:29 [notice] 32#32: using the "epoll" event method
2024/09/07 16:33:29 [notice] 32#32: nginx/1.23.3
2024/09/07 16:33:29 [notice] 32#32: built by gcc 10.2.1 20210110 (Debian 10.2.1-6)
2024/09/07 16:33:29 [notice] 32#32: OS: Linux 5.15.0-113-generic
2024/09/07 16:33:29 [notice] 32#32: getrlimit(RLIMIT_NOFILE): 1048576:1048576
2024/09/07 16:33:29 [notice] 33#33: start worker processes
root@7a86d1b1da47:/etc/nginx/conf.d# 2024/09/07 16:33:29 [notice] 33#33: start worker process 34
2024/09/07 16:33:29 [notice] 33#33: start worker process 35重要
补充:如果希望查看容器内部的进程,不推荐直接在容器内部使用 ps 等指令,因为有可能没有下载在里面,而是在宿主机器中使用 Docker 的内置命令,如下命令行。
# 查看容器内部的进程列表
$ sudo docker top 7a86d1b1da47
UID PID PPID C STIME TTY TIME CMD
root 530223 530202 0 Sep07 ? 00:00:00 bash
root 531963 530223 0 00:35 ? 00:00:00 nginx: master process nginx
systemd+ 531964 531963 0 00:35 ? 00:00:00 nginx: worker process
systemd+ 531965 531963 0 00:35 ? 00:00:00 nginx: worker process重要
补充:这里提前说明一下,开发者可以设置镜像文件基于不同系统中,而 Docker 会根据这个设置来模拟不同 Shell,这样方便别人使用镜像文件进行二次开发,而实际的镜像文件如果没有打开 Shell,运行的时候只会调用 Docker 根据本地系统调用模拟出来的系统调用来支持实际需要运行的镜像程序。
重要
补充:有些情况下我们不得不进入容器内部进行配置,但是每次都需要安装各种各样的指令实在事太过于繁琐,因此您可以尝试使用 apt install -y busybox 这个 busybox 内部集成了相当多的 Linux 指令,总体积却非常的小,不过每次执行指令就需要在指令前面加上 busybox,例如 busybox ls,如果容器不需要使用则可以使用 apt --purge autoremove busybox 来卸载。
然后我们开始进行关于 Nginx 的配置,这个方面需要您自己去补补课了,我也有结合官方文档写过类似的新手教程。不过这里我们简单点,不配置什么,就用 Nginx 默认的配置来试试。在浏览器中访问宿主机的 ip:8086 端口,看看能不能访问得到,结果如下。
# 容器对应的日志输出
root@7a86d1b1da47:/etc/nginx/conf.d# 120.235.190.119 - - [07/Sep/2024:16:42:18 +0000] "GET / HTTP/1.1" 200 615 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36" "-"
2024/09/07 16:42:19 [error] 39#39: *2 open() "/usr/share/nginx/html/favicon.ico" failed (2: No such file or directory), client: 120.235.190.119, server: localhost, request: "GET /favicon.ico HTTP/1.1", host: "47.121.195.60:8086", referrer: "http://47.121.195.60:8086/"
120.235.190.119 - - [07/Sep/2024:16:42:19 +0000] "GET /favicon.ico HTTP/1.1" 404 555 "http://47.121.195.60:8086/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36" "-"如果退出了容器的命令行,由于设置了 --rm 就会导致容器停止并且被输出。
# 观察退出容器的现象
root@7a86d1b1da47:/etc/nginx/conf.d# exit
exit
$ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
果然无法访问了...
重要
补充:您也可以尝试使用容器来管理数据库,例如 MySQL Redis,这样数据库就可以借用镜像文件来做迁移,非常方便,至于如何迁移,我后面再来实践。
9.2.使用自己制作的镜像文件
开发者在构建 Docker 镜像时,会在一个叫 Dockerfile 中指定基础镜像(通常包含操作系统),这个基础镜像决定了容器运行时的操作系统环境。其他开发者 pull 拉取下来后,使用 Docker 运行,并且 Docker 的容器化可以保证镜像在任何环境产生一样的效果,并且具有隔离性,原理我们之前提到过。
待补充...
9.3.实时更新容器的资源限制
# 实时更新容器的资源限制
# 使用 stats 来观察容器的资源限制, 如果资源不够使用可以进行拓展
$ sudo docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1bd761f8ab2d nginx:1.23.3 "/docker-entrypoint.…" 29 hours ago Up 29 hours 0.0.0.0:8086->80/tcp, :::8086->80/tcp my_nginx
# 调整内存
$ docker container update -m 300m --memory-swap 600m
# -m 300m 指定容器的内存限制为 300MB, 这表示容器在物理内存中最多只能使用 300MB 内存。一旦容器的内存使用达到这个限制, 它将尝试释放内存, 否则将会触发内存不足(OOM)
# --memory-swap 600m: 设置容器的总内存和 swap 限制为 600MB
$ CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
1bd761f8ab2d my_nginx 0.08% 64.46MiB / 300MiB 21.49% 15.2MB / 505kB 201kB / 31.2MB 6
# 调整处理器
$ sudo docker update --cpu-period=100000 --cpu-quota=10000 my_nginx
my_nginx
$ CONTAINER ID NAME CPU % MEM USAGE / LIMIT MEM % NET I/O BLOCK I/O PIDS
1bd761f8ab2d my_nginx 0.09% 64.52MiB / 300MiB 21.51% 17MB / 589kB 201kB / 32.8MB 69.4.宿主机容器主机共享文件
重要
补充:另外 cp 也算是一种共享机制,虽然使用起来是比较麻烦的,但有些特殊情况也很有用。
# 宿主机容器主机共享文件
# 创建需要共享的文件夹
$ mkdir ~/temp
# 我们启动一个 nginx 服务, 并且共享一个目录
$ sudo docker container run --name my_nginx -p 8086:80 -v /home/您的用户名/temp:/temp -d nginx:1.23.3
1bd761f8ab2d77f03ea1deb218d4aaf593f4ae0da3e6496c3c37af2cf58f59b2
# 查看容器的运行状态
$ sudo docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1bd761f8ab2d nginx:1.23.3 "/docker-entrypoint.…" 33 seconds ago Up 33 seconds 0.0.0.0:8086->80/tcp, :::8086->80/tcp my_nginx
# 编写文件
$ echo "Hello container" > ~/temp/test.txt
$ cat ~/temp/test.txt
Hello container
# 检查是否共享
$ sudo docker container exec -it my_nginx bash
root@1bd761f8ab2d:/# ls
bin dev docker-entrypoint.sh home lib64 mnt proc run srv temp usr
boot docker-entrypoint.d etc lib media opt root sbin sys tmp var
root@1bd761f8ab2d:/# cd temp/
root@1bd761f8ab2d:/temp# ls
test.txt
root@1bd761f8ab2d:/temp# cat test.txt
Hello container # 确实是实时共享了这个文件
# 试试能不能从宿主数据其他非共享文件夹中的文件直接拷贝到容器主机内部
$ mkdir other
$ echo "Hello container~~~" > ~/other/test.txt
$ sudo docker container cp /home/ljp/other/test.txt my_nginx:/temp
Successfully copied 2.05kB to my_nginx:/temp
$ sudo docker container exec -it my_nginx bash
root@1bd761f8ab2d:/# cd temp/
root@1bd761f8ab2d:/temp# ls
test.txt
root@1bd761f8ab2d:/temp# cat test.txt
Hello container~~~ # 果然内容发送了改变9.5.离库迁移现有镜像和容器
9.5.1.迁移镜像文件
# 离库迁移现有镜像文件
# 迁移镜像
# >>> Centos 下的 Docker >>>
$ cd ~ && mkdir swap # 创建一个共享目录
$ sudo chmod 777 swap # 保证共享目录所有人均可使用
# <<< end <<<
# >>> Ubuntu 下的 Docker >>>
$ sudo docker image ls # 查询当前拥有的镜像
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx 1.23.4 a7be6198544f 16 months ago 142MB
limou3434/my_test_repository 0.0.1 a7be6198544f 16 months ago 142MB
limou3434/my_test_repository 0.1.0 a7be6198544f 16 months ago 142MB
limou3434/my_test_repository 1.0.0 a7be6198544f 16 months ago 142MB
nginx 1.23.3 ac232364af84 18 months ago 142MB
$ sudo docker image save limou3434/my_test_repository:1.0.0 -o limou3434_my_test_repository_1_0_0.tar # 制作镜像压缩包
$ ls # 查看压缩包是否存在
limou3434_my_test_repository_1_0_0.tar
$ sudo apt-get install scp
$ sudo scp limou3434_my_test_repository_1_0_0.tar 用户名@主机地址:/home/用户名/swap # 传输文件
# 可能需要先输入本机的管理员密码
# 然后肯定是需要输入对端服务器的管理员密码的
# ...等待传输完毕, 有点 hhhh, 将就用叭...
# <<< end <<<
# >>> Centos 下的 Docker >>>
$ ls ~/用户名/swap
limou3434_my_test_repository_1_0_0.tar # 成功接收到镜像压缩包
$ sudo systemctl start doxker # 启动 docker 守护进程
$ sudo docker image load -i ~/swap/limou3434_my_test_repository_1_0_0.tar
8cbe4b54fa88: Loading layer [==================================================>] 84.01MB/84.01MB
5dd6bfd241b4: Loading layer [==================================================>] 62.51MB/62.51MB
043198f57be0: Loading layer [==================================================>] 3.584kB/3.584kB
2731b5cfb616: Loading layer [==================================================>] 4.608kB/4.608kB
6791458b3942: Loading layer [==================================================>] 3.584kB/3.584kB
4d33db9fdf22: Loading layer [==================================================>] 7.168kB/7.168kB
Loaded image: limou3434/my_test_repository:1.0.0
$ sudo docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
limou3434/my_test_repository 1.0.0 a7be6198544f 16 months ago 142MB # 转化为本地的镜像文件
# <<< end <<<9.5.2.迁移镜像容器
# 离库迁移现有镜像容器
# >>> Ubuntu 下的 Docker >>>
$ sudo docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
1bd761f8ab2d nginx:1.23.3 "/docker-entrypoint.…" 2 days ago Up 2 days 0.0.0.0:8086->80/tcp, :::8086->80/tcp my_nginx
$ sudo docker container export my_nginx -o my_nginx.tar
$ ls
my_nginx.tar
$ sudo apt-get install rsync
Reading package lists... Done
Building dependency tree... Done
Reading state information... Done
rsync is already the newest version (3.2.7-0ubuntu0.22.04.2).
0 upgraded, 0 newly installed, 0 to remove and 193 not upgraded.
$ sudo rsync -avz --progress ~/my_nginx.tar 接受主机用户@接受主机地址:/home/接受主机用户名/temp
sending incremental file list
my_nginx.tar
320,359,936 100% 349.55kB/s 0:14:54 (xfr#1, to-chk = 0/1)
sent 126,043,159 bytes received 35 bytes 135,022.17 bytes/sec
total size is 320,359,936 speedup is 2.54
# <<< end <<<
# >>> Centos 下的 Docker >>>
$ ls
my_nginx.tar
$ sudo docker import my_nginx.tar my_nginx:2.0.0
sha256:6f143ac5b5dde633bea81eb0f4c9a56967e48df069fc81d8e03c3584422badcf
$ sudo docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
my_nginx 2.0.0 6f143ac5b5dd 6 seconds ago 314MB
# <<< end <<<9.6.使用存储卷达到灾难恢复
# 使用存储卷达到灾难恢复
# 拉取 MySQL 镜像文件
$ docker pull mysql:5.7
5.7: Pulling from library/mysql
20e4dcae4c69: Pull complete
1c56c3d4ce74: Pull complete
e9f03a1c24ce: Pull complete
68c3898c2015: Pull complete
6b95a940e7b6: Pull complete
90986bb8de6e: Pull complete
ae71319cb779: Pull complete
ffc89e9dfd88: Pull complete
43d05e938198: Pull complete
064b2d298fba: Pull complete
df9a4d85569b: Pull complete
Digest: sha256:4bc6bc963e6d8443453676cae56536f4b8156d78bae03c0145cbe47c2aad73bb
Status: Downloaded newer image for mysql:5.7
docker.io/library/mysql:5.7
# 创建并运行容器
$ sudo docker container run --name mysql-demo -e MYSQL_ROOT_PASSWORD=limou3434 -it -d -v /home/您的用户名/data/myworkdir/mysqldata:/var/lib/mysql mysql:5.7 # 注意这里使用环境参数 MYSQL_ROOT_PASSWORD 来传递 MySQL 密码
# 登陆容器私用数据库
$ sudo docker container exec -it mysql-demo bash
bash-4.2# mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.44 MySQL Community Server (GPL)
Copyright (c) 2000, 2023, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)
mysql> create database limou;
Query OK, 1 row affected (0.00 sec)
mysql> use limou;
Database changed
mysql> create table student(sno char(3), sname varchar(10));
Query OK, 0 rows affected (0.02 sec)
mysql> insert into student values('1', 'dimou'),('2', 'eimou');
Query OK, 2 rows affected (0.01 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from student;
+------+-------+
| sno | sname |
+------+-------+
| 1 | dimou |
| 2 | eimou |
+------+-------+
2 rows in set (0.00 sec)
mysql> exit
Bye
bash-4.2# exit
exit
# 查看数据库的存储位置
$ cd ~/data
$ sudo tree * -L 2
\myworkdir
└── mysqldata
├── auto.cnf
├── ca-key.pem
├── ca.pem
├── client-cert.pem
├── client-key.pem
├── ib_buffer_pool
├── ibdata1
├── ib_logfile0
├── ib_logfile1
├── ibtmp1
├── limou # 我们自己创建的数据库
├── mysql
├── mysql.sock -> /var/run/mysqld/mysqld.sock
├── performance_schema
├── private_key.pem
├── public_key.pem
├── server-cert.pem
├── server-key.pem
└── sys
www
├── 404.html
├── 50x.html
├── access.log
├── error.log
├── image1.jpg
├── image2.jpg
└── index.html
0 directories, 7 files
# 查看持久化的内容, 可以看到变成了二进制几乎无法阅读
sudo ls myworkdir/mysqldata/limou
db.opt student.frm student.ibd
$ sudo cat myworkdir/mysqldata/limou/db.opt
default-character-set=latin1
default-collation=latin1_swedish_ci
$ sudo cat myworkdir/mysqldata/limou/student.frm
�
0 8�// �� InnoDB
�@
P@) snosname��
�sno�sname�%
$ sudo cat myworkdir/mysqldata/limou/student.ibd
�-�;��@!��������������������������&&�������������������������-�;��_M͔�t$M͔�t$<�"��_���������������������������������i������������������������������������������������������������������������������������������������������������������������������������������������������i���������������������������������������������������������������������������������������������������������������������������������<�"��_��r�����������E����)�2infimum
supremum" � dimou�� � eimoupc��r���%
# 假设此时发生意外(容器因为停电而停止), 并且有人失误删除了容器以节省磁盘空间
$ sudo docker stop mysql-demo
$ sudo docker rm mysql-demo
# 重新正确启动容器
$ sudo docker container run --name mysql-demo -e MYSQL_ROOT_PASSWORD=limou3434 -it -d -v /home/ljp/data/myworkdir/mysqldata:/var/lib/mysql mysql:5.7
dc88ef57752021a84ec67841fefd94ada18836bd1364f75a0366ef7ff2008340
# 重新进入容器的 bash 进行交互
$ sudo docker container exec -it mysql-demo bash
# 重新登录数据库
bash-4.2# mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.44 MySQL Community Server (GPL)
Copyright (c) 2000, 2023, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
# 重新查看数据库和数据表以及其中的数据, 可以看到灾难恢复成功, 数据没有发生丢失
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| limou |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
mysql> use limou;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+-----------------+
| Tables_in_limou |
+-----------------+
| student |
+-----------------+
1 row in set (0.00 sec)
mysql> select * from student;
+------+-------+
| sno | sname |
+------+-------+
| 1 | dimou |
| 2 | eimou |
+------+-------+
2 rows in set (0.00 sec)
mysql> exit
Bye
bash-4.2# exit
exit
# 尝试删除存储卷
sudo rm -rf ~/data/myworkdir
# 果然会发生数据灾难, 持久化的数据不见了
sudo docker container exec -it mysql-demo bash
bash-4.2# mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.7.44 MySQL Community Server (GPL)
Copyright (c) 2000, 2023, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
+--------------------+
1 row in set (0.00 sec)
mysql> exit
Bye
bash-4.2# exit
exit
$ sudo docker container stop mysql-demo
mysql-demo
$ sudo docker container rm mysql-demo
mysql-demo9.7.使用桥接网络来转化流量
之前我们只是简单验证了下网络的一些配置文件,还没有做过实际的通信,这里实践一下五个模式下的网络转发过程。
9.7.1.验证 Bridge 网络模型
注意
注意:这里放上之前已经提到的文本,避免您反复跳转...
- 描述:
bridge驱动会在Docker主机上创建一个Linux网桥。默认情况下,连接到同一网桥的容器可以相互通信 - 应用场景:当多个容器需要在同一台
Docker主机上通信时使用。是Docker容器的默认网络模式。 - 特点:容器与宿主机隔离,容器间可以使用同一个虚拟网桥进行通信
# 验证 Bridge 网络模型(准备阶段)
# 拉取镜像文件
$ sudo docker pull nginx:1.23.3
1.23.3: Pulling from library/nginx
f1f26f570256: Already exists
84181e80d10e: Already exists
1ff0f94a8007: Already exists
d776269cad10: Already exists
e9427fcfa864: Already exists
d4ceccbfc269: Already exists
Digest: sha256:f4e3b6489888647ce1834b601c6c06b9f8c03dee6e097e13ed3e28c01ea3ac8c
Status: Downloaded newer image for nginx:1.23.3
docker.io/library/nginx:1.23.3
# 尝试使用 Docker 自己创建一个虚拟网卡
$ sudo docker network create --driver bridge --gateway=172.28.0.1 --subnet=172.28.0.0/16 my_bridge_network
464051de9f9b26ba28623406e73d8d1641be9b72652aed1238f82d3f44fb04ac
# 后台启动多个容器的同时接入同一张网卡
$ sudo docker container run --name test_1_nginx --network my_bridge_network -it -d -p 8085:80 nginx:1.23.3
$ sudo docker container run --name test_2_nginx --network my_bridge_network -it -d -p 8086:80 nginx:1.23.3
$ sudo docker container run --name test_3_nginx --network my_bridge_network -it -d -p 8087:80 nginx:1.23.3
# 查看是否都正确启动
$ sudo docker container ls
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
16571b8f9543 nginx:1.23.3 "/docker-entrypoint.…" 23 seconds ago Up 22 seconds 0.0.0.0:8087->80/tcp, :::8087->80/tcp test_3_nginx
a1491841311d nginx:1.23.3 "/docker-entrypoint.…" About a minute ago Up About a minute 0.0.0.0:8086->80/tcp, :::8086->80/tcp test_2_nginx
a7353ee991b6 nginx:1.23.3 "/docker-entrypoint.…" 2 minutes ago Up 2 minutes 0.0.0.0:8085->80/tcp, :::8085->80/tcp test_1_nginx
# 检查虚拟网卡配置和容器内部网络地址的配置
$ sudo docker network ls
NETWORK ID NAME DRIVER SCOPE
d76247a506b9 bridge bridge local
641718df1c49 host host local
464051de9f9b my_bridge_network bridge local
a65bf697fc48 none null local
$ sudo docker network inspect my_bridge_network
# ...
"Config": [
{
"Subnet": "172.28.0.0/16", # 虚拟网卡掩码配置
"Gateway": "172.28.0.1" # 虚拟网卡主机配置
}
]
# ...
$ sudo docker container inspect test_1_nginx | tail -n 53 | head -n 50
"NetworkSettings": {
"Bridge": "",
"SandboxID": "4de877a452aa50c3999a51afa5bc121f5c1d1e439a55b7011fc7338bb7d51b4a",
"SandboxKey": "/var/run/docker/netns/4de877a452aa",
"Ports": {
"80/tcp": [
{
"HostIp": "0.0.0.0",
"HostPort": "8085"
},
{
"HostIp": "::",
"HostPort": "8085"
}
]
},
"HairpinMode": false,
"LinkLocalIPv6Address": "",
"LinkLocalIPv6PrefixLen": 0,
"SecondaryIPAddresses": null,
"SecondaryIPv6Addresses": null,
"EndpointID": "",
"Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"IPAddress": "",
"IPPrefixLen": 0,
"IPv6Gateway": "",
"MacAddress": "",
"Networks": {
"my_bridge_network": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"MacAddress": "02:42:ac:1c:00:02",
"DriverOpts": null,
"NetworkID": "464051de9f9b26ba28623406e73d8d1641be9b72652aed1238f82d3f44fb04ac",
"EndpointID": "6fb08c6d19bd5506050279e459a607fea43ef82c398858ebc6b5313c8f17a93d",
"Gateway": "172.28.0.1",
"IPAddress": "172.28.0.2", # 的确在子网内部
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"DNSNames": [
"test_1_nginx",
"a7353ee991b6"
]
}
}
$ sudo docker container inspect test_2_nginx | tail -n 53 | head -n 50
"NetworkSettings": {
"Bridge": "",
"SandboxID": "2c9961bbeed6b60289f2672b87372d47bad2875cacc1b0df3860b92f5c62e8e2",
"SandboxKey": "/var/run/docker/netns/2c9961bbeed6",
"Ports": {
"80/tcp": [
{
"HostIp": "0.0.0.0",
"HostPort": "8086"
},
{
"HostIp": "::",
"HostPort": "8086"
}
]
},
"HairpinMode": false,
"LinkLocalIPv6Address": "",
"LinkLocalIPv6PrefixLen": 0,
"SecondaryIPAddresses": null,
"SecondaryIPv6Addresses": null,
"EndpointID": "",
"Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"IPAddress": "",
"IPPrefixLen": 0,
"IPv6Gateway": "",
"MacAddress": "",
"Networks": {
"my_bridge_network": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"MacAddress": "02:42:ac:1c:00:03",
"DriverOpts": null,
"NetworkID": "464051de9f9b26ba28623406e73d8d1641be9b72652aed1238f82d3f44fb04ac",
"EndpointID": "872c02e1a7ef40c71f70c2d71ea2eaf9ecc065e7ca3e9da27873ea1088f6c899",
"Gateway": "172.28.0.1",
"IPAddress": "172.28.0.3", # 的确在子网内部
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"DNSNames": [
"test_2_nginx",
"a1491841311d"
]
}
}
$ sudo docker container inspect test_3_nginx | tail -n 53 | head -n 50
"NetworkSettings": {
"Bridge": "",
"SandboxID": "846fb2aa7584d79010271d0a84e6f87c4980ba7c07fc1377ab10426de9c4c38a",
"SandboxKey": "/var/run/docker/netns/846fb2aa7584",
"Ports": {
"80/tcp": [
{
"HostIp": "0.0.0.0",
"HostPort": "8087"
},
{
"HostIp": "::",
"HostPort": "8087"
}
]
},
"HairpinMode": false,
"LinkLocalIPv6Address": "",
"LinkLocalIPv6PrefixLen": 0,
"SecondaryIPAddresses": null,
"SecondaryIPv6Addresses": null,
"EndpointID": "",
"Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"IPAddress": "",
"IPPrefixLen": 0,
"IPv6Gateway": "",
"MacAddress": "",
"Networks": {
"my_bridge_network": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"MacAddress": "02:42:ac:1c:00:04",
"DriverOpts": null,
"NetworkID": "464051de9f9b26ba28623406e73d8d1641be9b72652aed1238f82d3f44fb04ac",
"EndpointID": "e0c51bbb157f571890c9fd7c602ea227831d7e3e24695e2214dcb48d2499039b",
"Gateway": "172.28.0.1",
"IPAddress": "172.28.0.4", # 的确在子网内部
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"DNSNames": [
"test_3_nginx",
"16571b8f9543"
]
}
}现在通过我们的虚拟网卡 my_bridge_network 组建了一个容器局域网,这个网络和主机网络是隔离开的,要验证也不困难,只需要在一个容器内部使用 curl -i 主机地址 访问其他容器看看是否能生效返回 nginx 的默认网页即可。
# 验证 Bridge 网络模型(实验阶段)
# 您启动容器的时候可能 nginx 就已经被启动了, 如果没有您手动启动即可, 这里只演示效果
# 检查 Nginx 是否已经启动
$ sudo docker container top test_1_nginx
UID PID PPID C STIME TTY TIME CMD
root 916565 916544 0 12:31 ? 00:00:00 nginx: master process nginx -g daemon off;
systemd+ 916617 916565 0 12:31 ? 00:00:00 nginx: worker process
systemd+ 916618 916565 0 12:31 ? 00:00:00 nginx: worker process
# 进入容器安装 curl
$ sudo docker container exec -it test_1_nginx bash
root@a7353ee991b6:/# apt-get update
# ... 一些输出
$ apt-get install curl
# 尝试访问其他容器部署的 Nginx 默认网址, 并且访问其他两个地址进行对比
# 尝试访问
root@a7353ee991b6:/# curl -i 172.28.0.0
curl: (7) Failed to connect to 172.28.0.0 port 80: No route to host
# 访问容器 1
root@a7353ee991b6:/# curl -i 172.28.0.1
HTTP/1.1 200 OK
Server: nginx/1.18.0 (Ubuntu)
Date: Thu, 19 Sep 2024 06:58:44 GMT
Content-Type: text/html
Content-Length: 612
Last-Modified: Tue, 21 Apr 2020 14:09:01 GMT
Connection: keep-alive
ETag: "5e9efe7d-264"
Accept-Ranges: bytes
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
body {
width: 35em;
margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif;
}
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
# 访问容器 2
root@a7353ee991b6:/# curl -i 172.28.0.2
HTTP/1.1 200 OK
Server: nginx/1.23.3
Date: Thu, 19 Sep 2024 06:58:46 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 13 Dec 2022 15:53:53 GMT
Connection: keep-alive
ETag: "6398a011-267"
Accept-Ranges: bytes
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
# 访问容器 3
root@a7353ee991b6:/# curl -i 172.28.0.3
HTTP/1.1 200 OK
Server: nginx/1.23.3
Date: Thu, 19 Sep 2024 06:58:48 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 13 Dec 2022 15:53:53 GMT
Connection: keep-alive
ETag: "6398a011-267"
Accept-Ranges: bytes
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
# 访问容器 4
root@a7353ee991b6:/# curl -i 172.28.0.4
HTTP/1.1 200 OK
Server: nginx/1.23.3
Date: Thu, 19 Sep 2024 06:58:49 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 13 Dec 2022 15:53:53 GMT
Connection: keep-alive
ETag: "6398a011-267"
Accept-Ranges: bytes
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
# 尝试访问
root@a7353ee991b6:/# curl -i 172.28.0.5
curl: (7) Failed to connect to 172.28.0.5 port 80: No route to host成功了,由此可以看到 Docker 的强大之处,不过别兴奋,我们还有其他几个网络模型要研究!
重要
补充:只要虚拟网卡由分配给容器地址,那这个网卡就不会被用户误删除,您可以自己尝试一下。
重要
补充:另外这里有一个比较有趣的,就是虚拟网卡分配给不同容器的同时,本身的配置信息也会发生变动,方便用户查看该网卡组建的局域网的详细信息。
# 分配好容器地址后, 重新查看网卡的详细信息
$ sudo docker network inspect my_bridge_network
[
{
"Name": "my_bridge_network",
"Id": "464051de9f9b26ba28623406e73d8d1641be9b72652aed1238f82d3f44fb04ac",
"Created": "2024-09-19T12:29:49.966495201+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.28.0.0/16",
"Gateway": "172.28.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": { # 这里之后的信息之前是没有看到的
"16571b8f9543f8a5ab9f594b5cc71fba19b32eab3faeef1065abcfd76bf90205": {
"Name": "test_3_nginx",
"EndpointID": "e0c51bbb157f571890c9fd7c602ea227831d7e3e24695e2214dcb48d2499039b",
"MacAddress": "02:42:ac:1c:00:04",
"IPv4Address": "172.28.0.4/16",
"IPv6Address": ""
},
"a1491841311d729f0c6746ec36b4b153e071fe68c4aa2542c39f57950dbeb50a": {
"Name": "test_2_nginx",
"EndpointID": "872c02e1a7ef40c71f70c2d71ea2eaf9ecc065e7ca3e9da27873ea1088f6c899",
"MacAddress": "02:42:ac:1c:00:03",
"IPv4Address": "172.28.0.3/16",
"IPv6Address": ""
},
"a7353ee991b62be50107c3a18c7a0b2ad0c4e66bbafe773f28e87ce8a77cdf66": {
"Name": "test_1_nginx",
"EndpointID": "6fb08c6d19bd5506050279e459a607fea43ef82c398858ebc6b5313c8f17a93d",
"MacAddress": "02:42:ac:1c:00:02",
"IPv4Address": "172.28.0.2/16",
"IPv6Address": ""
}
},
"Options": {},
"Labels": {}
}
]如果容器停止运行或被删除,就会导致断开和虚拟网卡的连接,类似路由器组建的子网中掉线的主机,上面网卡的详细信息也会把这个容器主机对应的信息剔除。
重要
补充:其实 Docker 还支持 DNS 域名解析,不过这里的域名是指容器主机的名字,但是安装 Docker 时一开始创建的默认网络 bridge 本身却不开启这种行为(这个您验证一下即可,这里只展示自定义网络的 DNS 现象)。值得注意的是,curl 在访问 http 服务器时,默认访问 80 端口,因此我们直接访问容器名字,看看能不能得到 Nginx 的默认首页即可。
# 尝试直接访问其他容器的名字
$ sudo docker container exec -it test_1_nginx bash
root@a7353ee991b6:/# curl -i test_2_nginx
HTTP/1.1 200 OK
Server: nginx/1.23.3
Date: Thu, 19 Sep 2024 07:47:16 GMT
Content-Type: text/html
Content-Length: 615
Last-Modified: Tue, 13 Dec 2022 15:53:53 GMT
Connection: keep-alive
ETag: "6398a011-267"
Accept-Ranges: bytes
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>9.7.2.验证 Host 网络模型
注意
注意:这里放上之前已经提到的文本,避免您反复跳转...
- 描述:容器与
Docker主机之间没有网络隔离,容器直接使用主机的网络栈(原理其实就是和宿主主机使用同一个网络命名空间) - 应用场景:当容器需要直接使用主机网络,避免
NAT和额外的网络层时使用,通常用于高性能需求场景 - 特点:网络与宿主机共享,但其他资源如文件系统、进程等仍被隔离
# 验证 Host 网络模型(实验阶段)
# 由于 host 网络的特殊性, hsot 虚拟网卡只需要存在一个就够了, 无需用户自己创建, 只需要在 docker run 的时候指定类型就可以, Docker 已经帮我们提供了这个虚拟网卡
# 查看 Docker 提供的 host 网卡
$ sudo docker network ls
NETWORK ID NAME DRIVER SCOPE
d76247a506b9 bridge bridge local
641718df1c49 host host local
464051de9f9b my_bridge_network bridge local
a65bf697fc48 none null local
# 然后启动一个容器, 注意网络类型的选择
$ sudo docker container run --name test_nginx --network host -it -d nginx:1.23.3
4d41cf6db2ce3afdf20cd4141e0182dc1857628315b1bea4dc321ed8505e4a05
# 进入容器内部检查 nginx 配置并且启动
# 不过由于 Nginx 默认的端口是 80, 并且这个 80 此时因为网络类型为 host, 因此必须保证宿主主机上的 80 端口无进程使用才行, 否则容器会一直启动失败(这也侧面证明了网络资源是共用的)
$ sudo docker container run --name test_nginx --network host -it -d nginx:1.23.3
$ sudo docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
81631868df4a nginx:1.23.3 "/docker-entrypoint.…" 45 seconds ago Up 45 seconds test_nginx
$ curl 127.0.0.1:80 # 明明是在宿主本机, 并且宿主主机没有部署 Nginx, 但是却可以访问的 Nginx 的首页, 这其实就是容器 Nginx 服务的首页
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>9.7.3.验证 Container 网络模型
注意
注意:这里放上之前已经提到的文本,避免您反复跳转...
- 描述:新创建的容器与指定的现有容器共享同一个网络。它们共享
IP地址和端口等网络资源 - 应用场景:当两个容器需要共享相同的网络环境时使用,但文件系统和进程仍然独立
- 特点:两个容器通过
lo回环设备通信,共享网络资源但其他资源隔离,但是会导致容器之间产生依赖性,如果启动顺序不正确就会导致部分涉及到网络的容器无法启动
那么这种网络类型需要使用 create 来创建么?其实也不需要,可以在新容器启动的时候,使用 --network ontainer:旧容器名 来让新创建的容器复用旧容器的网络。
不过我们这里就不能使用 Nginx 来演示了,因为镜像文件中的 Nginx 默认在容器启动的时候就启动 Nginx 导致多个容器在一套网络资源中会发生冲突,最终必有一个容器无法正常运行,因此我们换一个软件的镜像吧,我们其实只需要简单测试下网络即可。
# 验证 Container 网络模型(实验阶段)
# 拉取 busybox 软件的镜像文件
$ sudo docker pull busybox:1.35
1.35: Pulling from library/busybox
a9b82d1f2d6e: Pull complete
Digest: sha256:98ad9d1a2be345201bb0709b0d38655eb1b370145c7d94ca1fe9c421f76e245a
Status: Downloaded newer image for busybox:1.35
docker.io/library/busybox:1.35
$ sudo docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx 1.23.3 ac232364af84 18 months ago 142MB
busybox 1.35 95f45f955052 2 years ago 4.27MB
# 尝试创建相关的容器
$ sudo docker container run --name test_1_busybox --network my_bridge_network -it -d busybox:1.35
165bf004b9c097f0c85e9a213fee48fb4df5a27cd01bfbc8c84b7c6e8ceb87c5
$ sudo docker container run --name test_2_busybox --network container:test_1_busybox -it -d busybox:1.35
d415e72454cd06d444a839ea3624082aa4106102483d2ebdaa854c7f8617194b
$ sudo docker container ls -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
d415e72454cd busybox:1.35 "sh" 10 seconds ago Up 10 seconds test_2_busybox
165bf004b9c0 busybox:1.35 "sh" 49 seconds ago Up 49 seconds test_1_busybox
# 验证 Container 网络
$ sudo docker container exec -it test_1_busybox sh
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:1C:00:02
inet addr:172.28.0.2 Bcast:172.28.255.255 Mask:255.255.0.0 # 可以看到和下面分配到地址是一样的
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:13 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1086 (1.0 KiB) TX bytes:0 (0.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ # exit
$ sudo docker container exec -it test_2_busybox sh
/ # ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:1C:00:02
inet addr:172.28.0.2 Bcast:172.28.255.255 Mask:255.255.0.0 # 可以看到和上面分配到地址是一样的
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:13 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1086 (1.0 KiB) TX bytes:0 (0.0 B)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ # exit
# 上面分配到的 id 地址相同意味着两个容器的网络资源可以理解为同一台主机上的网络资源(不过其他资源依旧是按照两个主机来进行隔离)
# 查询旧容器之前绑定的网卡
$ sudo docker network ls
NETWORK ID NAME DRIVER SCOPE
4eb8fda8a3ac bridge bridge local
641718df1c49 host host local
464051de9f9b my_bridge_network bridge local
a65bf697fc48 none null local
$ sudo docker network inspect my_bridge_network
[
{
"Name": "my_bridge_network",
"Id": "464051de9f9b26ba28623406e73d8d1641be9b72652aed1238f82d3f44fb04ac",
"Created": "2024-09-19T12:29:49.966495201+08:00",
"Scope": "local",
"Driver": "bridge",
"EnableIPv6": false,
"IPAM": {
"Driver": "default",
"Options": {},
"Config": [
{
"Subnet": "172.28.0.0/16",
"Gateway": "172.28.0.1"
}
]
},
"Internal": false,
"Attachable": false,
"Ingress": false,
"ConfigFrom": {
"Network": ""
},
"ConfigOnly": false,
"Containers": {
"165bf004b9c097f0c85e9a213fee48fb4df5a27cd01bfbc8c84b7c6e8ceb87c5": {
"Name": "test_1_busybox",
"EndpointID": "69127132408d8c4dba7c6e2d2f5b8e6a7bf17e173797cdf8254ac0ca9f74a330",
"MacAddress": "02:42:ac:1c:00:02",
"IPv4Address": "172.28.0.2/16",
"IPv6Address": ""
}
},
"Options": {},
"Labels": {}
}
]
# 可以再进一步验证一下
$ sudo docker container inspect test_1_busybox
# ...
"NetworkSettings": {
"Bridge": "",
"SandboxID": "c2e33dc0cd635370167417840c50130e1fe2585ae52c8099c2df32ab1a0f8b1d",
"SandboxKey": "/var/run/docker/netns/c2e33dc0cd63",
"Ports": {},
"HairpinMode": false,
"LinkLocalIPv6Address": "",
"LinkLocalIPv6PrefixLen": 0,
"SecondaryIPAddresses": null,
"SecondaryIPv6Addresses": null,
"EndpointID": "",
"Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"IPAddress": "",
"IPPrefixLen": 0,
"IPv6Gateway": "",
"MacAddress": "",
"Networks": {
"my_bridge_network": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"MacAddress": "02:42:ac:1c:00:02",
"DriverOpts": null,
"NetworkID": "464051de9f9b26ba28623406e73d8d1641be9b72652aed1238f82d3f44fb04ac",
"EndpointID": "69127132408d8c4dba7c6e2d2f5b8e6a7bf17e173797cdf8254ac0ca9f74a330",
"Gateway": "172.28.0.1", # 可以看到网关地址
"IPAddress": "172.28.0.2", # 还有和之前 ifconfig 一样的地址分配结果
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"DNSNames": [
"test_1_busybox",
"165bf004b9c0"
]
}
}
# ...
$ sudo docker container inspect test_2_busybox
# ...
"NetworkSettings": {
"Bridge": "",
"SandboxID": "",
"SandboxKey": "",
"Ports": {},
"HairpinMode": false,
"LinkLocalIPv6Address": "",
"LinkLocalIPv6PrefixLen": 0,
"SecondaryIPAddresses": null,
"SecondaryIPv6Addresses": null,
"EndpointID": "",
"Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"IPAddress": "",
"IPPrefixLen": 0,
"IPv6Gateway": "",
"MacAddress": "",
"Networks": {} # 此时这里设置为空, 这意味着该新容器在地址上是依附于旧容器的(两者相同地址, 共享网络资源)
}
# ...9.7.4.验证 None 网络模型
注意
注意:这里放上之前已经提到的文本,避免您反复跳转...
- 描述:
Docker容器拥有自己的网络命名空间,但不进行任何网络配置,容器没有网络功能(除了本地环回)。 - 应用场景:需要完全隔离的容器时使用,尤其是对网络安全有严格要求的场景
- 特点:容器无网卡、无
IP、无路由,完全网络隔离
这次是终于可以使用 --network none 来指定这种特殊的网络类型了,这种创建和理解都不困难,这里就不过多演示了,您自己试一试吧...
# 验证 None 网络模型(实验阶段)
$ sudo docker container run --name test_busybox --network none -it busybox:1.35 sh
/ # ifconfig
lo Link encap:Local Loopback # 可以发现没有类似 eth0 等网卡字眼了, 只剩下一个用于本地环回的本地网卡
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
/ # exit9.7.5.验证 Overlay 网络模型
[!WARNING]
注意:这里放上之前已经提到的文本,避免您反复跳转...
- 描述:用于跨多台
Docker主机的容器通信,适用于Docker Swarm集群中,将多个Docker守护进程连接在一起(前提是宿主主机们需要都能相互通信)- 应用场景:当需要多个
Docker主机上的容器协同工作时使用,如分布式集群服务- 特点:跨主机的容器通信,集群内的服务可以相互通信
不过由于现代的 k8s 才是当下的主流,并且本系列文章不打算解说关于集群架构的知识,只是聚焦于一台主机上的容器,因此这部分知识我会在 k8s 中进行解说。
9.8.用编排技术做多容器管理
接下来我们 根据 Docker Compose 官方文档来实操 一下,这里使用 Python 的 Flask 框架,该应用程序在 Redis 中具有一个访问计数器。
确保 安装好 Docker Compose 我这里是用插件的方式安装
创建以下文件
app.py# app.py import time import redis from flask import Flask app = Flask(__name__) cache = redis.Redis(host='redis', port=6379) def get_hit_count(): retries = 5 while True: # 没有出现异常的话 try: return cache.incr('hits') # 使用 incr() 方法对 hits 键的值进行自增 # 如果出现异常的话 except redis.exceptions.ConnectionError as exc: # 如果异常超过 5 次就终止请求 if retries == 0: raise exc # 出现异常就让程序停滞 0.5 s retries -= 1 time.sleep(0.5) @app.route('/') def hello(): count = get_hit_count() return 'Hello World! I have been seen {} times.\n'.format(count)安装
Python相关依赖,编辑requirements.txt依赖文件# requirements.txt Flask redis这个时候可以简单尝试运行代码作为测试,直接在本地部署并且在本地访问即可,不过需要把
app.py中的'redis'暂时改为'127.0.0.1'进行本地测试,并且手动使用sudo apt update && sudo apt install redis-server && sudo systemctl start redis-server安装本地Redis,使用pip install -r requirements.txt安装Flask应用的依赖。# 测试代码 # >>> begin: 第一个终端 >>> # 直接安装依赖方便测试 $ pip install -r requirements.txt # 以调试模式运行 Flask 应用 $ flask run --debug * Debug mode: on WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Running on http://127.0.0.1:5000 Press CTRL+C to quit * Restarting with stat * Debugger is active! * Debugger PIN: 144-689-084 127.0.0.1 - - [24/Oct/2024 19:18:39] "GET / HTTP/1.1" 200 - 127.0.0.1 - - [24/Oct/2024 19:18:42] "GET / HTTP/1.1" 200 - 127.0.0.1 - - [24/Oct/2024 19:18:43] "GET / HTTP/1.1" 200 - 127.0.0.1 - - [24/Oct/2024 19:18:44] "GET / HTTP/1.1" 200 - # <<< end <<< # >>> begin: 第二个终端 >>> $ curl -i http://127.0.0.1:5000 HTTP/1.1 200 OK Server: Werkzeug/3.0.4 Python/3.12.3 Date: Thu, 24 Oct 2024 11:18:39 GMT Content-Type: text/html; charset=utf-8 Content-Length: 39 Connection: close Hello World! I have been seen 1 times. $ curl -i http://127.0.0.1:5000 HTTP/1.1 200 OK Server: Werkzeug/3.0.4 Python/3.12.3 Date: Thu, 24 Oct 2024 11:18:42 GMT Content-Type: text/html; charset=utf-8 Content-Length: 39 Connection: close Hello World! I have been seen 2 times. $ curl -i http://127.0.0.1:5000 HTTP/1.1 200 OK Server: Werkzeug/3.0.4 Python/3.12.3 Date: Thu, 24 Oct 2024 11:18:43 GMT Content-Type: text/html; charset=utf-8 Content-Length: 39 Connection: close Hello World! I have been seen 3 times. $ curl -i http://127.0.0.1:5000 HTTP/1.1 200 OK Server: Werkzeug/3.0.4 Python/3.12.3 Date: Thu, 24 Oct 2024 11:18:44 GMT Content-Type: text/html; charset=utf-8 Content-Length: 39 Connection: close Hello World! I have been seen 4 times. # <<< end <<<注意
注意:如果是容器集群,可以使用
'redis'作为域名进行访问,因此上面的app.py中没有写出具体的ip地址,还请您在本地测试结束后改回'redis'编写
Dockerfile文件# Dockerfile # syntax=docker/dockerfile:1 # 从 Python 3.10 镜像开始构建镜像(Alpine 是轻量级 Linux 发行版) FROM python:3.10-alpine # 设置工作目录 WORKDIR /code # 设置 Flask 指令的环境变量, 指向 Flask 应用的主文件 ENV FLASK_APP=app.py # Flask 运行的地址 ENV FLASK_RUN_HOST=0.0.0.0 # 安装所需要的依赖 # 如果有防火墙限制可以使用阿里云的, 或者传递代理环境变量 # RUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.aliyun.com/g' /etc/apk/repositories RUN apk add --no-cache gcc musl-dev linux-headers # 拷贝本地的 requirements.txt 到镜像中的工作目录 COPY requirements.txt requirements.txt # 指定在镜像制作时要执行的指令 RUN pip install -r requirements.txt # 声明容器将监听 5000 端口, 但这不会自动映射端口, 只会编写到文档中供用户作为提示 EXPOSE 5000 # 拷贝当前目录下的所有文件到镜像的工作目录中 COPY . . # 指定在容器启动时要执行的指令 CMD ["flask", "run", "--debug"]重要
补充:如果依赖项没有变化,则分开书写
COPY的写法可以使这一依赖层可以被缓存,避免每次镜像构建时都重新安装依赖,从而加快构建速度。编写
compose.yaml文件# compose.yaml services: web: build: . ports: - "8000:5000" redis: image: "redis:alpine"此
Compose文件定义了两个服务:web和redis。web服务使用当前目录中从Dockerfile构建的镜像。然后,它将容器和主机绑定到暴露的端口8000,这个示例服务使用Flask网络服务器的默认端口5000redis服务使用从Docker Hub注册表拉取的公共Redis镜像
然后使用
docker compose up开始启动多个容器(如果配置名字是自定义的,则可以使用-f指定配置路径)# 启动多个容器 $ docker compose up [+] Running 3/1 ✔ Network flask_test_default Created 0.1s ✔ Container flask_test-redis-1 Created 0.1s ✔ Container flask_test-web-1 Created 0.1s Attaching to redis-1, web-1 redis-1 | 1:C 24 Oct 2024 15:15:34.232 # WARNING Memory overcommit must be enabled! Without it, a background save or replication may fail under low memory condition. Being disabled, it can also cause failures without low memory condition, see https://github.com/jemalloc/jemalloc/issues/1328. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory = 1' for this to take effect. redis-1 | 1:C 24 Oct 2024 15:15:34.232 * oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo redis-1 | 1:C 24 Oct 2024 15:15:34.232 * Redis version=7.4.1, bits=64, commit=00000000, modified=0, pid=1, just started redis-1 | 1:C 24 Oct 2024 15:15:34.232 # Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf redis-1 | 1:M 24 Oct 2024 15:15:34.232 * monotonic clock: POSIX clock_gettime redis-1 | 1:M 24 Oct 2024 15:15:34.233 * Running mode=standalone, port=6379. redis-1 | 1:M 24 Oct 2024 15:15:34.233 * Server initialized redis-1 | 1:M 24 Oct 2024 15:15:34.233 * Ready to accept connections tcp web-1 | * Serving Flask app 'app.py' web-1 | * Debug mode: on web-1 | WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. web-1 | * Running on all addresses (0.0.0.0) web-1 | * Running on http://127.0.0.1:5000 web-1 | * Running on http://172.18.0.3:5000 web-1 | Press CTRL+C to quit web-1 | * Restarting with stat web-1 | * Debugger is active! web-1 | * Debugger PIN: 851-404-503 # 如果打开了其他终端则可以使用下面指令来查看 $ docker compose ps NAME IMAGE COMMAND SERVICE CREATED STATUS PORTS flask_test-redis-1 redis:alpine "docker-entrypoint.s…" redis 10 minutes ago Up 10 minutes 6379/tcp flask_test-web-1 flask_test-web "flask run --debug" web 10 minutes ago Up 10 minutes 0.0.0.0:8000->5000/tcp, [::]:8000->5000/tcp $ docker compose logs # 查看 Flask 应用的日志访问网站,可以在本地访问,也可以远程访问(您可以拿您的浏览器访问您
http://服务器ip地址:8000来访问)# 命令行中本地访问 $ curl http://localhost:8000 Hello World! I have been seen 1 times.不过我们每次修改代码,按照
Flask应用的特性,只要修改代码并且保存就会自动热重载,但是上面却丧失了这一功能,原因是因为就算我们使用--debug来启动Flask应用,也需要进入容器内部才能修改代码,在宿主主机上修改代码文件是不会自动跟踪拷贝到容器内部的。因此需要在容器编排时就对相关的代码文件进行跟踪,因此我们需要进一步修改编排配置文件。# compose.yaml services: web: build: . ports: - "8000:5000" develop: # 开发模式下 watch: # 跟踪代码 - action: sync # 这是同步操作 path: . # 宿主主机监视路径 target: /code # 容器主机目标路径 redis: image: "redis:alpine"而之前运行的容器,我们使用
docker compose down卸载后docker compose up --bulid --watch重新制作镜像,启动新的容器。然后尝试修改宿主主机上的代码即可观察现象。# 开发模式下同步更新 # >>> begin: 1 号终端 >>> $ cat app.py # app.py import time import redis from flask import Flask app = Flask(__name__) cache = redis.Redis(host='redis', port=6379) def get_hit_count(): retries = 5 while True: # 没有出现异常的话 try: return cache.incr('hits') # 使用 incr() 方法对 hits 键的值进行自增 # 如果出现异常的话 except redis.exceptions.ConnectionError as exc: # 如果异常超过 5 次就终止请求 if retries == 0: raise exc # 出现异常就让程序停滞 0.5 s retries -= 1 time.sleep(0.5) @app.route('/') def hello(): count = get_hit_count() return 'Hello World! I have been seen {} times.\n'.format(count) $ docker compose down $ docker compose up --bulid --watch # <<< end <<< # >>> begin: 2 号终端 >>> $ vim app.py $ cat app.py # app.py import time import redis from flask import Flask app = Flask(__name__) cache = redis.Redis(host='redis', port=6379) def get_hit_count(): retries = 5 while True: # 没有出现异常的话 try: return cache.incr('hits') # 使用 incr() 方法对 hits 键的值进行自增 # 如果出现异常的话 except redis.exceptions.ConnectionError as exc: # 如果异常超过 5 次就终止请求 if retries == 0: raise exc # 出现异常就让程序停滞 0.5 s retries -= 1 time.sleep(0.5) @app.route('/') def hello(): count = get_hit_count() # return '{}\n'.format(count) return 'Hello World! I have been seen {} times.\n'.format(count) # <<< end <<< # >>> begin: 1 号终端 >>> # 在上述修改被保存后立刻就出现了以下输出 # ... ⦿ Syncing service "web" after 1 changes were detected web-1 | * Detected change in '/code/app.py', reloading web-1 | * Restarting with stat web-1 | * Debugger is active! web-1 | * Debugger PIN: 779-253-463 # ... # <<< ed <<< # >>> begin: 2 号终端 >>> $ curl -i http://127.0.0.1:8000 HTTP/1.1 200 OK Server: Werkzeug/3.0.4 Python/3.10.15 Date: Fri, 25 Oct 2024 00:33:42 GMT Content-Type: text/html; charset=utf-8 Content-Length: 2 Connection: close 2 # <<< end <<<实际上两个服务我们可以拆分为两个文件,新创建一个名为
infra.yaml的新Compose文件。将Redis服务从原本的compose.yaml文件中剪切并粘贴到新的infra.yaml文件中。确保在文件顶部添加services顶级属性。您的infra.yaml文件现在应该如下所示:# infra.yaml services: redis: image: "redis:alpine"在你的
compose.yaml文件中,添加include顶级属性以及infra.yaml文件的路径。# compose.yaml include: - infra.yaml services: web: build: . ports: - "8000:5000" develop: watch: - action: sync path: . target: /code运行
docker compose down && docker compose up --build --watch以使用更新的Compose文件构建应用程序并运行它。您应该在浏览器中看到输出消息。# 拆分服务 # 拆分配置文件 $ vim compose.yaml $ vim infra.yaml $ cat compose.yaml infra.yaml # compose.yaml include: - infra.yaml services: web: build: . ports: - "8000:5000" develop: watch: - action: sync path: . target: /code # infra.yaml services: redis: image: "redis:alpine" # 重新构建和启动 $ docker compose down && docker compose up --bulid --watch $ curl -i http://127.0.0.1:8000 HTTP/1.1 200 OK Server: Werkzeug/3.0.4 Python/3.10.15 Date: Fri, 25 Oct 2024 00:57:41 GMT Content-Type: text/html; charset=utf-8 Content-Length: 2 Connection: close 3
到这里最基本的使用您已了解,只需要继续查看官方文档即可,不过涉及到跨主机的容器编排,我们推荐使用 k8s,并且也不推荐使用前面的 Overlay 网络。
这里再给出一个例子,这次的例子会尽可能编写较多的配置,旨在得到一个万用配置,以运行多个 Linux 为例,这次的需求是使用 Docker Compose 来编排多个容器租借给他人使用。
不过我们来重新整理下关于 yml 文件的常见配置顶级元素(也就是配置文件中没有任何缩进的字段)以及旗下的子元素(子字段),相关的资源可以 在官方文档中学习详细的配置。
- [version]:
Compose不再使用version来选择一个确切的模式来验证Compose文件,本系列用的是当前(2024.10.25)的最新版本Docker Compose工具,因此这个顶级元素已经不再需要 - name: 定义项目名称,默认是配置文件的父目录作为项目名称,可以使用
docker compose ls来验证,并且会作为环境变量COMPOSE_PROJECT_NAME被暴露以进行插值和环境变量解析(就是定义完成就可以使用这个环境变量了) - services: 定义所有的服务,所有的服务构成一个项目
- <service_name>: 用户自定义的服务
- build:/image: 指定构建镜像,如果没有自己的镜像文件,就只需要使用
image后指定镜像名:版本号即可- context: 上下文路径,通常填写目录,指定构建镜像的构建目录
- dockerfile: 指定镜像文件名称,通常填写镜像文件名称,可以是默认名称也可以是自定义名称
- args: 将参数传递给
Dockerfile中对应的ARG指令,这样可以编写出更加通用的镜像文件 - target: 构建目标阶段(这和
Dockerfile的构建阶段编写有关,允许只运行到某一个阶段)
- container_name: 镜像运行后对应的容器名称,可以使用
docker container ls -a来验证 - command: 用于覆盖
Dockerfile中的CMD指令,也是在容器启动时执行,在容器运行时执行 - mem_limit: 内存限制
- cpus: 处理器数量限制
- cpuset: 处理器对象限制
- devices: 驱动映射
- ports: 端口映射
- volumes: 存储映射
- restart: 选项可以使用以下几种策略:
no默认值,不重启容器。always总是重启容器,即使容器手动停止,系统重启后也会自动启动。on-failure仅在容器非正常退出时重启,例如崩溃退出。unless-stopped容器会自动重启,除非手动停止它。
另外,可以通过配置 .env 文件来让 docker compose 来读取变量,下面我们来完成使用 Docker Compose 来编排多个容器租借给他人使用的需求(这种行为其实就是在模拟云服务器厂商的行为)。
# 编写镜像文件
# vim gzs_linux_learn_container_dockerfile
# cat gzs_linux_learn_container_dockerfile
# 默认使用 Ubuntu 20.04 作为基础镜像
ARG UBUNTU_VERSION=20.04
FROM ubuntu:${UBUNTU_VERSION}
# 设置时区和避免交互模式
ENV DEBIAN_FRONTEND=noninteractive
ENV container=docker
# 更新软件包并安装常用工具, 包括 OpenSSH 服务
RUN apt update && apt install -y \
sudo \
htop \
openssh-server \
vim \
curl \
net-tools \
wget \
git \
gcc \
python3 \
&& apt clean
# 创建 SSH 配置目录并生成 SSH 密钥
RUN mkdir /var/run/sshd && ssh-keygen -A
# 配置 SSH 服务允许使用密码登录,设置 root 密码为 rootubuntu
RUN echo 'root:rootubuntu' | chpasswd && \
sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
# 启动 ssh 服务并保持容器在前台运行
CMD ["/usr/sbin/sshd", "-D"]# 编写编排文件
# vim gzs_linux_learn_container_compose.yml
# cat gzs_linux_learn_container_compose.yml
name: gzs-linux-learn-container # 设置顶级元素 name
services: # 设置顶级元素 service
container1: # 服务
build: # 镜像构建路径
context: .
dockerfile: gzs_linux_learn_container_dockerfile
args:
UBUNTU_VERSION: "${UBUNTU_VERSION}" # 从 config.env 文件中获取变量
container_name: Gzs-Ubuntu2004-1 # 生成的容器名
command: ["/usr/sbin/sshd", "-D"] # 为避免意外还是覆盖了启动指令, 默认启动 sshd 服务
mem_limit: 4G # 最大内存限制
cpus: '2.0' # 最大处理核数
cpuset: "0,1" # 指定处理核心
devices: # 管理设备
- /dev/null:/dev/nvidia0 # 设置 gpu 资源, 禁止 gpu 使用
ports:
- "9000:22" # 映射主机的 9000 端口到容器的 22 端口 (SSH)
- "9001:80" # 映射主机的 9001 端口到容器的 80 端口 (HTTP)
- "9002:443" # 映射主机的 9002 端口到容器的 443 端口 (HTTPS)
- "9003:3306" # 映射主机的 9003 端口到容器的 3306 端口 (MySQL)
- "9004:8080" # 显示备用 HTTP 端口
- "9005:6379" # 映射主机的 9005 端口到容器的 6379 端口 (Redis)
- "9006:5432" # 映射主机的 9006 端口到容器的 5432 端口 (PostgreSQL)
volumes: # 挂载目录
- /home/ljp/data/docker-compose/docker1:/home:rw
restart: always # 设置自动重启策略
container2: # 第二个服务
build:
context: .
dockerfile: gzs_linux_learn_container_dockerfile
args:
UBUNTU_VERSION: "${UBUNTU_VERSION}"
container_name: Gzs-Ubuntu2004-2 # 生成的容器名
command: ["/usr/sbin/sshd", "-D"] # 启动 sshd 服务
mem_limit: 4G # 最大内存限制
cpus: '2.0' # 最大处理核数
cpuset: "0,1" # 指定处理核心
devices:
- /dev/null:/dev/nvidia0 # 设置 gpu 资源, 禁止 gpu 使用
ports:
- "9100:22" # 映射主机的 9100 端口到容器的 22 端口 (SSH)
- "9101:80" # 映射主机的 9101 端口到容器的 80 端口 (HTTP)
- "9102:443" # 映射主机的 9102 端口到容器的 443 端口 (HTTPS)
- "9103:3306" # 映射主机的 9103 端口到容器的 3306 端口 (MySQL)
- "9104:8080" # 显示备用 HTTP 端口
- "9105:6379" # 映射主机的 9105 端口到容器的 6379 端口 (Redis)
- "9106:5432" # 映射主机的 9106 端口到容器的 5432 端口 (PostgreSQL)
volumes: # 挂载目录
- /home/ljp/data/docker-compose/docker2:/home:rw
restart: always # 设置自动重启策略
container3: # 第三个服务
build:
context: .
dockerfile: gzs_linux_learn_container_dockerfile
args:
UBUNTU_VERSION: "${UBUNTU_VERSION}"
container_name: Gzs-Ubuntu2004-3 # 生成的容器名
command: ["/usr/sbin/sshd", "-D"] # 启动 sshd 服务
mem_limit: 4G # 最大内存限制
cpus: '2.0' # 最大处理核数
cpuset: "0,1" # 指定处理核心
devices:
- /dev/null:/dev/nvidia0 # 设置 gpu 资源, 禁止 gpu 使用
ports:
- "9200:22" # 映射主机的 9200 端口到容器的 22 端口 (SSH)
- "9201:80" # 映射主机的 9201 端口到容器的 80 端口 (HTTP)
- "9202:443" # 映射主机的 9202 端口到容器的 443 端口 (HTTPS)
- "9203:3306" # 映射主机的 9203 端口到容器的 3306 端口 (MySQL)
- "9204:8080" # 显示备用 HTTP 端口
- "9205:6379" # 映射主机的 9205 端口到容器的 6379 端口 (Redis)
- "9206:5432" # 映射主机的 9206 端口到容器的 5432 端口 (PostgreSQL)
volumes: # 挂载目录
- /home/ljp/data/docker-compose/docker3:/home:rw
restart: always # 设置自动重启策略# 编写变量文件
$ cat config.env
UBUNTU_VERSION=20.04# 运行编排工具
$ sudo docker compose -f gzs_linux_learn_container_compose.yml --env-file config.env up --build -d注意
注意:有看不懂的地方查询一下即可。
重要
补充:以下三个字段的区别。
RUN用于在构建镜像时执行命令,通常用于安装软件包、设置环境等CMD用于设置容器启动时的默认命令和参数,可以被docker run命令行参数覆盖command用于覆盖Dockerfile中的CMD指令,也是在容器启动时执行,在容器运行时执行
如果镜像文件默认的启动指令正确,则可以不设置设个覆盖指令。
警告
警告:上述配置文件的写法其实不太现代(尤其是在资源限制这里),如果需要现代写法最好直接查询官方文档...
10.Docker 的软件
这一小节主要是讲解一些常见的基于 Docker 的软件配置问题,旨在提高我们初始项目、部署项目的速度,这里会讲解到一些常见软件的相关配置。不过首先有一个前提条件:下面的组件在项目源代码中,都拥有一个单独的目录做一些持久化操作,我推荐每个目录都存在 ./docker/<组件名> 下,并且统一使用 docker-compose 来进行快速部署。
10.1.Nginx
待补充...
10.2.MySQL
部署的时候,最头疼的其实就是 MySQL 的初始化过程,安装 MySQL 后总是会遇到各种问题阻碍我们的开发进度(例如关于用户和密码的配置)。首先我建议,既然您都使用 Docker 进行数据库快速部署了,那么用户名干脆直接使用 root,保持 Linux 的习惯,除非您需要将多个项目的数据存储到统一的地方,不然这个数据库容器只需要一个账户就够用了(开发阶段就不要给自己受限了)。
# ./docker-compose.yaml
services:
# 存储
<项目名称>-mysql:
image: mysql:latest
container_name: work-creative-space-mysql
mem_limit: 400m
cpus: "0.5"
ports:
- "3306:3306"
restart: always
privileged: true
environment:
TZ: Asia/Shanghai
MYSQL_ROOT_PASSWORD: Qwe54188_
volumes:
- "./docker/mysql/data/:/var/lib/mysql/" # 持久化目录
- "./docker/mysql/init/:/docker-entrypoint-initdb.d/" # 初始化目录
networks:
- <项目名称>-network
networks:
<项目名称>-network:
name: <项目名称>-network10.3.Redis
待补充...
10.4.Elasticsearch
待补充...
10.5.Minio
待补充...