1.事务的理解
前要:在网络服务中,如果对
CURD不加限制,会出现什么问题?在多个客户端同时向一个卖票服务器买票时(假设票数只剩一张),
A客户端让数据库内的票数count减1,但是还没来得及更新数据,又有B服务器查询数据库,此时B服务器看到票数还是1,又进行了减1操作,导致一张票被同时卖了两次。
CURD 的过程需要满足什么条件,才能解决上述问题呢?
- 买票的过程得应该是原子操作(要么抢到,要么没抢)
- 买票的过程中不能被相互影响(不能被互相影响,要割裂/独立开来)
- 买完票后应该要永久有效(必须要做持久化,不能只是在内存中操作)
- ef
- 买前和买后都是确定的状态(不能出现中间状态,要保证一致性)
1.事务的理解
1.1.事务的概念
事务简单来理解就是 一组 DML 语句,也就是一组用于数据操作(插入数据、删除数据...)的语句。
事务主要处理操作量大,复杂度高的数据,这些数据往往需要多条 SQL 语句来构成。
但是事务还不仅仅是多条语句的集合,还必须保证四个属性(ACID)才能保证安全运行事务:
原子性(Atomicity):一组
DML语句/一个事务,要么全部成功,要么全部失败,这是由MySQL提供的机制来保障的。一致性(Consistency):在事务开始和结束以后,数据库的完整性没有被破坏,写入的数据必须完全符合所有的预设规则(在
MySQL中,一致性时被其他三个属性来保证的,但是需要数据库和用户来配合,才能得到一致性)隔离性(Isolation):防止多个事务并发执行时由于交叉执行导致的数据不一致问题,事务隔离有不同的等级
(1)读未提交(
Read Uncommitted)(2)读提交(
Read Committed)(3)可重复读(
Repeatable Read)(4)串行化(
Serialzable)持久性(Durability):事务处理完后,对表中数据的影响是永久的(哪怕系统挂了也不会丢失),也就是持久化
注意:学习事务一定要在使用数据库的用户视角来理解。
事务在 MySQL 内也一定是一个具体对象,这就需要先描述再组织。
另外,事务不是 MySQl 天然就存在,而是为了在应用程序访问数据库的时候,能够简化编程模型,不需要考虑各种潜在并发问题、网络问题,用户只需要提交和回滚。因此,事务的本质是为了应用层服务的,而不是面向数据库内部。
1.2.事务的版本
MySQL 中只有使用了 Innodb 数据库引擎的数据库或数据表才可以支持事务,其他基本都不支持。
# 查看 MySQL 的引擎是否支持事务
show engines \G
*************************** 1. row ***************************
Engine: InnoDB
Support: DEFAULT
Comment: Supports transactions, row-level locking, and foreign keys
Transactions: YES
XA: YES
Savepoints: YES
*************************** 2. row ***************************
Engine: MRG_MYISAM
Support: YES
Comment: Collection of identical MyISAM tables
Transactions: NO
XA: NO
Savepoints: NO
*************************** 3. row ***************************
Engine: MEMORY
Support: YES
Comment: Hash based, stored in memory, useful for temporary tables
Transactions: NO
XA: NO
Savepoints: NO
*************************** 4. row ***************************
Engine: BLACKHOLE
Support: YES
Comment: /dev/null storage engine (anything you write to it disappears)
Transactions: NO
XA: NO
Savepoints: NO
*************************** 5. row ***************************
Engine: MyISAM
Support: YES
Comment: MyISAM storage engine
Transactions: NO
XA: NO
Savepoints: NO
*************************** 6. row ***************************
Engine: CSV
Support: YES
Comment: CSV storage engine
Transactions: NO
XA: NO
Savepoints: NO
*************************** 7. row ***************************
Engine: ARCHIVE
Support: YES
Comment: Archive storage engine
Transactions: NO
XA: NO
Savepoints: NO
*************************** 8. row ***************************
Engine: PERFORMANCE_SCHEMA
Support: YES
Comment: Performance Schema
Transactions: NO
XA: NO
Savepoints: NO
*************************** 9. row ***************************
Engine: FEDERATED
Support: NO
Comment: Federated MySQL storage engine
Transactions: NULL
XA: NULL
Savepoints: NULL
9 rows in set (0.00 sec)2.事务的操作
2.1.做一些准备工作
开始之前,先设置一下隔离性(后面提及)。
# 设置隔离性
mysql> set global transaction isolation level READ UNCOMMITTED;
Query OK, 0 rows affected (0.00 sec)
mysql> select @@tx_isolation;
+------------------+
| @@tx_isolation |
+------------------+
| READ-UNCOMMITTED |
+------------------+
1 row in set, 1 warning (0.00 sec)首先,事务有两种提交方式:
- 自动提交
- 手动提交
# 查看事务提交方式
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.01 sec)可以用 SET 来改变 MySQL 的自动提交方式。
# 取消事务自动提交
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | OFF |
+---------------+-------+
1 row in set (0.00 sec)
mysql> set autocommit=1;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.00 sec)然后我们切换超级用户,使用 netstat -nltp 是一个用于显示网络连接、路由表和网络接口信息的命令行工具查看 MySQL 是否成功运行且占用端口号。
# 查看网络状态
# netstat -nltp
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp6 0 0 :::3306 :::* LISTEN 7404/mysqld原本是应该使用 Windows11 的 cmd 来远程访问 Centos7 云服务的 MySQL 服务,不过需要提前在 Windows11 中提前下载好 MySQL,所以我们先用本地的两个客户端来模拟,后续再来详细了解。
然后修改事务等级,不然有些现象会看不到。
# 客户端中设置事务隔离级别并且重启检查
mysql> set global transaction isolation level read uncommitted;
Query OK, 0 rows affected (0.00 sec)
mysql> quit
Bye
$ mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 32
Server version: 5.7.44 MySQL Community Server (GPL)
Copyright (c) 2000, 2023, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> select @@tx_isolation;
+------------------+
| @@tx_isolation |
+------------------+
| READ-UNCOMMITTED |
+------------------+
1 row in set, 1 warning (0.00 sec)启动两个 MySQL 客户端(模拟并发场景),然后其中一个客户端建立一个如下的表结构:
# 客户端1:创建表结构
create table if not exists account(
id int primary key,
name varchar(50) not null default '',
blance decimal(10,2) not null default 0.0
)ENGINE=InnoDB DEFAULT CHARSET=UTF8;# 客户端2:查看是否能看到 account 数据表
mysql> desc account;
+--------+---------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+---------------+------+-----+---------+-------+
| id | int(11) | NO | PRI | NULL | |
| name | varchar(50) | NO | | | |
| blance | decimal(10,2) | NO | | 0.00 | |
+--------+---------------+------+-----+---------+-------+
3 rows in set (0.00 sec)可以在一个客户端中查看连接情况,可以看到确实存在两个本地客户端。
# 客户端1:查看 MySQL 的连接情况
mysql> show processlist\G
*************************** 1. row ***************************
Id: 33
User: ljp
Host: localhost
db: limou_database
Command: Query
Time: 0
State: starting
Info: show processlist
*************************** 2. row ***************************
Id: 34
User: ljp
Host: localhost
db: limou_database
Command: Sleep
Time: 355
State:
Info: NULL
2 rows in set (0.00 sec)2.2.正常情况的事务
启动事务有两种方法:(1)start transaction; (2)begin
一旦开启事务,后续的 SQL 操作都属于同一个事务的部分。并且,我还设置了一个保存点(可选)
# 客户端1:启动事务
mysql> start transaction;
Query OK, 0 rows affected (0.00 sec)
mysql> savepoint s1;
Query OK, 0 rows affected (0.00 sec)# 客户端2:启动事务
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account;
Empty set (0.00 sec)然后进行插入工作,设置第二个保存点,并且查看插入的数据是否同步到另外一个客户端。
# 客户端1:插入数据
mysql> insert into account values (2, 'limou', 10000);
Query OK, 1 row affected (0.00 sec)
mysql> savepoint s2;
Query OK, 0 rows affected (0.00 sec)# 客户端2:查看数据
mysql> select * from account;
+----+-------+----------+
| id | name | blance |
+----+-------+----------+
| 2 | limou | 10000.00 |
+----+-------+----------+
1 row in set (0.00 sec)尝试插入更多的插入和设置保存点的操作,同时没插入一个记录,就检查客户端是否数据同步。
# 客户端1:插入数据和保存
mysql> savepoint s2;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into account values (1, 'dimou', 11030);
Query OK, 1 row affected (0.00 sec)
mysql> savepoint s3;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into account values (3, 'iimou', 10431);
Query OK, 1 row affected (0.00 sec)# 客户端2:每次插入,就查看一次数据表
mysql> select * from account;
+----+-------+----------+
| id | name | blance |
+----+-------+----------+
| 1 | dimou | 11030.00 |
| 2 | limou | 10000.00 |
+----+-------+----------+
2 rows in set (0.00 sec)
mysql> select * from account;
+----+-------+----------+
| id | name | blance |
+----+-------+----------+
| 1 | dimou | 11030.00 |
| 2 | limou | 10000.00 |
| 3 | iimou | 10431.00 |
+----+-------+----------+
3 rows in set (0.00 sec)如果我们突然后悔了,可以回滚事务。
# 客户端1:回滚事务
mysql> rollback to s3;
Query OK, 0 rows affected (0.00 sec)# 客户端2:查看回滚后的数据表
mysql> select * from account;
+----+-------+----------+
| id | name | blance |
+----+-------+----------+
| 1 | dimou | 11030.00 |
| 2 | limou | 10000.00 |
+----+-------+----------+
2 rows in set (0.00 sec)可以看到,数据表确实发生了回退,如果我们这个时候使用 COMMIT 就会提交本次事务。
# 客户端1:提交事务
mysql> commit;
Query OK, 0 rows affected (0.01 sec)补充:使用
roolback还可以将所有操作全部取消,但是一般很少这么做。
而事务只有在启动的时候才可以进行回滚操作,而一旦提交了就无法进行回滚。
2.3.异常情况的事务
如果其中一个服务端在事务状态下奔溃了会怎么样?其他客户端会自动回滚,也就是保证原子性,要么不做,要么就操作完。
# 客户端1:不断插入数据最后因为异常导致奔溃,插入一次就在客户端2中查看一次
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> insert into account values (3, 'eimou', 20431);
Query OK, 1 row affected (0.01 sec)
mysql> insert into account values (4, 'eimou', 30434);
Query OK, 1 row affected (0.00 sec)
mysql> ^C
mysql> Aborted# 客户端2:客户端1插入后不断查找数据表,最后检查奔溃后的数据表
mysql> select * from account;
+----+-------+----------+
| id | name | blance |
+----+-------+----------+
| 1 | dimou | 11030.00 |
| 2 | limou | 10000.00 |
+----+-------+----------+
2 rows in set (0.00 sec)
mysql> select * from account;
+----+-------+----------+
| id | name | blance |
+----+-------+----------+
| 1 | dimou | 11030.00 |
| 2 | limou | 10000.00 |
| 3 | eimou | 20431.00 |
| 4 | eimou | 30434.00 |
+----+-------+----------+
4 rows in set (0.00 sec)
mysql> select * from account; # 奔溃后,这里自动发生了回滚,回到开头
+----+-------+----------+
| id | name | blance |
+----+-------+----------+
| 1 | dimou | 11030.00 |
| 2 | limou | 10000.00 |
+----+-------+----------+
2 rows in set (0.00 sec)也有一些其他的情况会发生自动回滚(客户端因为关闭 shell 而导致退出),但是如果事务已经进行了提交(也就是使用了 COMMIT),就不会再进行回滚(包括因为崩溃造成的自动回滚)。
但是我们之前设置的自动提交又是什么鬼?不是事务会自动提交吗?从现象来看,无论是设置 autocommit 为 OFF 还是 ON 现象都是一样的结果(这个您可以自己实验一下),那这个 autocommit 究竟有什么用呢?您先知道一个点,只要是手动开启启动事务,就必须手动提交,和是否设置自动提交无关即可。
而对比有无设置 autocommit 的两种情况。
2.3.1.设置为 OFF
# 客户端1:设置 autocommit 为 OFF,然后在事务中进行删除记录
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.00 sec)
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | OFF |
+---------------+-------+
1 row in set (0.00 sec)
mysql> delete from account where id=3;
Query OK, 1 row affected (0.01 sec)
mysql> Aborted# 客户端2:不断查看数据表
mysql> select * from account; # 客户端1没删除之前
+----+-------+----------+
| id | name | blance |
+----+-------+----------+
| 1 | dimou | 11030.00 |
| 3 | timou | 50434.00 |
+----+-------+----------+
2 rows in set (0.00 sec)
mysql> select * from account; # 客户端1删除后
+----+-------+----------+
| id | name | blance |
+----+-------+----------+
| 1 | dimou | 11030.00 |
+----+-------+----------+
1 row in set (0.00 sec)
mysql> select * from account; # 客户端1奔溃后,发现记录恢复
+----+-------+----------+
| id | name | blance |
+----+-------+----------+
| 1 | dimou | 11030.00 |
| 3 | timou | 50434.00 |
+----+-------+----------+
2 rows in set (0.00 sec)2.3.2.设置为 ON
# 客户端1:进行删除操作,但是不在事务中删除后崩溃
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.00 sec)
mysql> delete from account where id=3;
Query OK, 1 row affected (0.01 sec)
mysql> Aborted# 客户端2:不断查看数据表
mysql> select * from account; # 客户端1没删除之前
+----+-------+----------+
| id | name | blance |
+----+-------+----------+
| 1 | dimou | 11030.00 |
| 3 | timou | 50434.00 |
+----+-------+----------+
2 rows in set (0.00 sec)
mysql> select * from account; # 客户端1删除后
+----+-------+----------+
| id | name | blance |
+----+-------+----------+
| 1 | dimou | 11030.00 |
+----+-------+----------+
1 row in set (0.00 sec)
mysql> select * from account; # 客户端1奔溃后,发现记录没有恢复
+----+-------+----------+
| id | name | blance |
+----+-------+----------+
| 1 | dimou | 11030.00 |
+----+-------+----------+
1 row in set (0.00 sec)而且就算客户端 2 之前有做 BEGIN,再 COMMIT 后也不会恢复数据。
以上测试说明,只要设置了 autocommit,就会把一条单纯的 SQL 语句单独看作一个事务,都会被自动 BEGIN 和 COMMIT。因此如果没设置 autocommit 就会因为没有 COMMIT 而导致数据回滚。
复习:再理一理,
BEGIN是开启事务处理,COMMIT是事务提交,防止回滚。
但是如果我们手动进行回滚呢?
# 客户端1:删除数据表,但是先 commit 再崩溃
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.00 sec)
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | OFF |
+---------------+-------+
1 row in set (0.01 sec)
mysql> delete from account where id=1;
Query OK, 1 row affected (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> Aborted# 客户端2:不断查看数据表
mysql> select * from account; # 客户端1删除记录前
+----+-------+----------+
| id | name | blance |
+----+-------+----------+
| 1 | dimou | 11030.00 |
+----+-------+----------+
1 row in set (0.00 sec)
mysql> select * from account; # 客户端1删除记录后
Empty set (0.00 sec)
mysql> select * from account; # 客户端1崩溃后,没有发生回滚
Empty set (0.00 sec)也侧面证明了:对于 InnoDB 里一条单纯的 SQL 就是一个完整的事务,最后都会因为 autocommit=ON 而自动提交(但是 SELECT 有点特殊,您先记住就行,因为 MySQL 有 MVCC)。
补充:
COMMIT操作实际上就是数据持久化的一种手段。
到这里就可以看到事务本身的 原子性(回滚) 和 持久性(提交)。
3.事务的隔离
3.1.隔离和隔离级别
但是事务的隔离性体现在哪里呢?为何需要隔离呢?不隔离可以吗?
一个 MySQL 服务可能会被多个客户端进程访问(一般都是程序直接连接数据库,命令行操作很少用到),访问的方式是以事务进行的。
而事务在上述小节中实现了原子性和持久性,事务注定有执行前、执行中、执行后,一旦异常就会回滚。为了保证事务在执行中,为了保证事务尽量不受干扰,就产生的隔离性,根据不同的干扰级别可以设置不同的隔离级别。
实际上,正常人的认知是:无论别的客户端 A 怎么对数据表怎么增删查改,另外一个客户端 B 要拿到最新的数据,不管两进程的先后顺序如何,都必须要先等待进程 A 完成一个事务。这个观点有问题吗?有点,举一个不恰当的例子,一个婴儿在出生后,不需要知道父母之前的经历,也能和父母一起创造新的经历,每个人只需要在自己生命周期内看到的世界也都是不一样的。这代表着:不一定需要获取最新的消息,只需要在自己的生命周期内看到该看到的就行,这就是隔离性。
在 MySQL 中,原子性不仅是在操作上原子,还体现在时间上。一个改表的 A 客户端先执行事务,一个查表的 B 客户端后执行事务,两者在执行中交叉进行。而 B 客户端执行得较慢,A 客户端执行得较快,那么 B 客户端是否应该立刻获取最新的数据呢?不应该!因为要保证隔离性,隔离运行中的事务。
因此隔离体现在运行事务中,而隔离性要隔离的程度就是隔离级别(根据内容重要度的不同,有些信息是可以不被隔离的,因此就有隔离级别),在交叉事务处理过程中,不同的事务级别分为:
- 读未提交(READ UNCOMMITTED):所有事务都可以看到其他事务没有提交的执行结果(相当于没有任何隔离性,实际生产中不太可能用到这个级别),我们之前的书写的事务代码,就是读未提交,没有进行
COMMIT也会看到事务中的操作后结果,而对方客户端一旦崩溃就和没有存在过一样,则本客户端发送回滚 - 读已提交(READ COMMITTED):只有对事务进行了
COMMIT,才能看到更新的数据表(一条单纯的SQL语句本身就被包装成一个事务,因此使用单纯的SQL语句会让所有客户端都读取到) - 可重复读(REPEATABLE READ):即便对方客户端提交了,哪怕是退出了,本客户端都无法实时知道更新结果,只有在本客户端退出了再次启动,才能看到更新后的新数据(这是
MySQL默认的隔离等级),但是可能会有幻读的问题。 - 串行化(SERIALIZABLE):事务隔离的最高级别,强制事务进行排序,使之不会相互冲突,确实解决了幻读的问题,但是会导致超时和锁竞争(太极端了,实际生产中很少用)
隔离级别,基本都是通过锁来实现的,不同的隔离级别使用的锁不一样,常见的有:表锁、行锁、读锁、写锁、间隙锁(GAP)、Next-Key 锁,简单认识一下就行。
3.2.查看和设置隔离级别
# 查看隔离级别
mysql> select @@global.tx_isolation; # 全局设置
+-----------------------+
| @@global.tx_isolation |
+-----------------------+
| READ-UNCOMMITTED |
+-----------------------+
1 row in set, 1 warning (0.00 sec)
mysql> select @@session.tx_isolation; # 当前会话设置
+------------------------+
| @@session.tx_isolation |
+------------------------+
| READ-UNCOMMITTED |
+------------------------+
1 row in set, 1 warning (0.00 sec)
mysql> select @@tx_isolation; # 默认显示会话设置(就是当前会话的设置)
+------------------+
| @@tx_isolation |
+------------------+
| READ-UNCOMMITTED |
+------------------+
1 row in set, 1 warning (0.00 sec)使用 SET {SESSION/GLOBAL} TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED/READ COMMITTED/REPEATABLE READ/SERIALIZABLE}; 就可以设置隔离级别。
而如果设置了全局设置,只会在下一次重启客户端时才会更新设置,一般一开始设置了隔离级别就不要修改了,最好保证隔离级别是一致的。
3.3.不同隔离级别带来的影响
再次强调,隔离主要是为了避免交叉事务出现问题。
3.3.1.读未提交
复习:读未提交,所有事务都可以看到其他事务没有提交的执行结果(相当于没有任何隔离性,实际生产中不太可能用到这个级别),我们之前的书写的事务代码,就是读未提交,没有进行
COMMIT也会看到事务中的操作后结果,而对方客户端一旦崩溃就和没有存在过一样,则本客户端发送回滚。
实际上之前已经做过了,最上面从设置隔离级别为 READ-UNCOMMITTED,后续的操作都是读未提交情景下的操作。
# 设置隔离级别
mysql> set global transaction isolation level READ UNCOMMITTED;
Query OK, 0 rows affected (0.00 sec)
# 然后重启两个客户端,分别查看隔离等级
mysql> select @@tx_isolation;
+------------------+
| @@tx_isolation |
+------------------+
| READ-UNCOMMITTED |
+------------------+
1 row in set, 1 warning (0.00 sec)# 客户端1:在事务中进行删除记录
mysql> set autocommit=0;
Query OK, 0 rows affected (0.00 sec)
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | OFF |
+---------------+-------+
1 row in set (0.00 sec)
mysql> delete from account where id=3;
Query OK, 1 row affected (0.01 sec)
mysql> Aborted # 这里奔溃后,就相当于没有进行 COMMIT# 客户端2:不断查看数据表
mysql> select * from account; # 客户端1没删除之前
+----+-------+----------+
| id | name | blance |
+----+-------+----------+
| 1 | dimou | 11030.00 |
| 3 | timou | 50434.00 |
+----+-------+----------+
2 rows in set (0.00 sec)
mysql> select * from account; # 客户端1删除后,还没提交就被读取到了,也就是“读未提交”
+----+-------+----------+
| id | name | blance |
+----+-------+----------+
| 1 | dimou | 11030.00 |
+----+-------+----------+
1 row in set (0.00 sec)
mysql> select * from account; # 客户端1奔溃后,发现记录恢复
+----+-------+----------+
| id | name | blance |
+----+-------+----------+
| 1 | dimou | 11030.00 |
| 3 | timou | 50434.00 |
+----+-------+----------+
2 rows in set (0.00 sec)这种未提交就可以被其他客户端读取的现象,也叫做 脏读 现象。
3.3.2.读已提交
复习:读已提交,只有对事务进行了
COMMIT,才能看到更新的数据表(一条单纯的SQL语句本身就被包装成一个事务,因此使用单纯的SQL语句会让所有客户端都读取到)。
# 设置隔离级别
mysql> set global transaction isolation level READ COMMITTED;
Query OK, 0 rows affected (0.00 sec)
# 然后重启两个客户端,分别查看隔离等级
mysql> select @@global.tx_isolation;
+-----------------------+
| @@global.tx_isolation |
+-----------------------+
| READ-COMMITTED |
+-----------------------+
1 row in set, 1 warning (0.00 sec)# 客户端1进行修改数据表
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update account set name='rimou' where id=2;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> commit;
Query OK, 0 rows affected (0.01 sec)# 客户端2不断进行查看
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account; # 没修改之前
+----+-------+---------+
| id | name | blance |
+----+-------+---------+
| 1 | limou | 1001.00 |
| 2 | dimou | 1023.00 |
| 3 | eimou | 2034.00 |
+----+-------+---------+
3 rows in set (0.00 sec)
mysql> select * from account; # 客户端1修改数据,但是没有进行 commit,继续在客户端2查看,发现数据仍旧没有被修改
+----+-------+---------+
| id | name | blance |
+----+-------+---------+
| 1 | limou | 1001.00 |
| 2 | dimou | 1023.00 |
| 3 | eimou | 2034.00 |
+----+-------+---------+
3 rows in set (0.00 sec)
mysql> select * from account; # 客户端1使用 commit,此时客户端2就会发现数据被修改了
+----+-------+---------+
| id | name | blance |
+----+-------+---------+
| 1 | limou | 1001.00 |
| 2 | rimou | 1023.00 |
| 3 | eimou | 2034.00 |
+----+-------+---------+
3 rows in set (0.00 sec)这种提交才可以被其他客户端读取的现象,在提交之前只能获得旧数据,这要看具体场景,才能决定是对是错的。
读提交有一个问题,一旦服务端 1 提交了,哪怕客户端 2 还处于事务中,也会读取到更新的数据,这在某些场景是错误的。理论上插入后更新数据表难道有错吗?有可能有错,提交确实是要让所有事务看到,但有时候不应该让运行中的事务看到(后面有个例子)。
3.3.3.可重复读
复习:可重复读,即便对方客户端提交了,哪怕是退出了,本客户端都无法实时知道更新结果,只有在本客户端退出了再次启动,才能看到更新后的新数据(这是
MySQL默认的隔离等级),但是会有幻读的问题。
# 设置隔离等级
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.01 sec)
mysql> set global transaction isolation level REPEATABLE READ;
Query OK, 0 rows affected (0.00 sec)
mysql> select @@global.tx_isolation;
+-----------------------+
| @@global.tx_isolation |
+-----------------------+
| REPEATABLE-READ |
+-----------------------+
1 row in set, 1 warning (0.00 sec)# 客户端1:更新数据表
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update account set name='iimou' where id=3;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> commit;
Query OK, 0 rows affected (0.00 sec)# 客户端2:不断查看,奔溃后再次查看
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account; # 在没有更新数据表内记录之前查询
+----+-------+---------+
| id | name | blance |
+----+-------+---------+
| 1 | limou | 1001.00 |
| 2 | rimou | 1023.00 |
| 3 | eimou | 2034.00 |
+----+-------+---------+
3 rows in set (0.00 sec)
mysql> select * from account; # 更新数据表内记录后查询
+----+-------+---------+
| id | name | blance |
+----+-------+---------+
| 1 | limou | 1001.00 |
| 2 | rimou | 1023.00 |
| 3 | eimou | 2034.00 |
+----+-------+---------+
3 rows in set (0.00 sec)
mysql> select * from account; # 在客户端1 commit 后再次查询
+----+-------+---------+
| id | name | blance |
+----+-------+---------+
| 1 | limou | 1001.00 |
| 2 | rimou | 1023.00 |
| 3 | eimou | 2034.00 |
+----+-------+---------+
3 rows in set (0.00 sec)
mysql> Aborted 3 # 客户端2奔溃了...
$ mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 54
Server version: 5.7.44 MySQL Community Server (GPL)
Copyright (c) 2000, 2023, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> use limou_database;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from account; # 在客户端2奔溃后重新启动
+----+-------+---------+
| id | name | blance |
+----+-------+---------+
| 1 | limou | 1001.00 |
| 2 | rimou | 1023.00 |
| 3 | iimou | 2034.00 | # 发现这里终于被修改了
+----+-------+---------+
3 rows in set (0.00 sec)例子:举一个超级生动具体的例子
一家公司招聘程序员时,原本规定了一个工作等级,于是开始招聘员工,假设招进了
A程序员,A程序员和HR敲定了自己的工资等级,最后成功入职。问题是,假设公司新出现了一个大型项目,需要招聘大量程序员,于是提高了薪资等级中的工资量。果然成功吸引了程序员B,程序员B和HR谈拢后,确定了和程序员A一样的等级,但是薪资却更高。而对于公司(黑心的)来说,不会直接告诉
A你这个等级的薪资提高了,所以我要给你提薪...A需要知道吗?不需要,你继续做你的工作就行了,在A的认知中,自己这个等级的薪资就是原先谈好的那么高。而一旦那一天工资项目出现问题,要进行裁员,就把
A给“优化”(裁员)了,但是最后公司发现,自己貌似开走了一个“大动脉”(你之前写的代码逻辑非常重要,没A不行的那种),最后又把你找回来,按照B的薪资招聘你。这就是“可重复读”,
A始终用的是旧的薪资等级来判断薪资,但是后来的B却是更新后的第二套薪资体系,可是在A就职期间(被重新招聘前),没必要知道更新后的薪资等级(不然A闹起来怎么办,笑)。员工
A:客户端 1员工
B:客户端 2
A就职期间:客户端 1 启动事务期间
B就职期间:客户端 2 启动事务期间
A离职时:客户端 1 结束事务进行提交
但是,在一些数据库中,在可重复隔离下,insert 的 sql 可能无法被屏蔽(因为隔离性是通过加锁和其他策略来实现的,但是混则很难通过加锁来实现),在多次查询的过程中,就有可能会查出更新的数据(也就是“幻读”)。但是 MySQL 中,在 RR 级别中修复了这个问题(使用 GAP+行锁),我们不在这里深入了解,这也是为什么该级别是默认级别的原因。
3.3.4.串行化
复习:串行化,事务隔离的最高级别,强制事务进行排序,使之不会相互冲突,确实解决了幻读的问题,但是会导致超时和锁竞争(太极端了,实际生产中很少用)
# 设置隔离级别
mysql> set global transaction isolation level SERIALIZABLE;
Query OK, 0 rows affected (0.01 sec)
mysql> select @@global.tx_isolation;
+-----------------------+
| @@global.tx_isolation |
+-----------------------+
| SERIALIZABLE |
+-----------------------+
1 row in set, 1 warning (0.00 sec)# 客户端1较后开启事务
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> update account set name='eimou' where id=2;
# 陷入阻塞状态,知道客户端2进行 commit 后才执行这条 sql
Query OK, 1 row affected (14.32 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> commit;
Query OK, 0 rows affected (0.01 sec)# 客户端2较先开启事务
mysql> begin;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account; # 客户端1还没修改前
+----+-------+---------+
| id | name | blance |
+----+-------+---------+
| 1 | limou | 1001.00 |
| 2 | rimou | 1023.00 |
| 3 | iimou | 2034.00 |
+----+-------+---------+
3 rows in set (0.00 sec)
mysql> select * from account; # 客户端1修改后
+----+-------+---------+
| id | name | blance |
+----+-------+---------+
| 1 | limou | 1001.00 |
| 2 | rimou | 1023.00 |
| 3 | iimou | 2034.00 |
+----+-------+---------+
3 rows in set (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
mysql> select * from account; # 客户端2提交后查看
+----+-------+---------+
| id | name | blance |
+----+-------+---------+
| 1 | limou | 1001.00 |
| 2 | rimou | 1023.00 |
| 3 | iimou | 2034.00 |
+----+-------+---------+
3 rows in set (0.00 sec)
mysql> Aborted # 客户端2崩溃、
$ mysql
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 61
Server version: 5.7.44 MySQL Community Server (GPL)
Copyright (c) 2000, 2023, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> use limou_database;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select * from account; # 重启后再次查看就发现依旧没有被修改
+----+-------+---------+
| id | name | blance |
+----+-------+---------+
| 1 | limou | 1001.00 |
| 2 | rimou | 1023.00 |
| 3 | iimou | 2034.00 |
+----+-------+---------+
3 rows in set (0.00 sec)
mysql> select * from account; # 只有客户端1提交了,才能看到修改
+----+-------+---------+
| id | name | blance |
+----+-------+---------+
| 1 | limou | 1001.00 |
| 2 | eimou | 1023.00 |
| 3 | iimou | 2034.00 |
+----+-------+---------+
3 rows in set (0.00 sec)注意,是事务之间串行化,不是进程之间串行化!
以上隔离等级就是 隔离性 的体现,而怎么体现一致性呢?
事务执行的结果,必须使数据库的一个一致性状态,转移到另外一个一致性状态。如果系统发生中断,某个事务未完成而被迫中止,而为改完的事务对数据库所做的修改已经写入数据库,此时数据库处于不正确、不一致的状态。因此是通过原子性(回滚)来保证一致的(而一致性和用户的逻辑强相关,由用户决定)。而其他三属性实际上都是围绕一致性来展开的,可以说 AID 是因,用户配合,C 是果。
注意:这关于事务这块还是比较复杂的,建议深入了解,反复学习。
4.隔离性的原理
数据库事务的并发场景有三个:
读-读:不存在任何问题,因此不需要并发控制读-写:有线程安全问题,可能造成事务隔离性问题(脏读、幻读、不可重复读),这种情况是主要的写-写:有线程安全问题,可能存在更新丢失问题(第一类更新丢失、第二类更新丢失)
读-读 我们几乎不需要讨论,重点讨论 读-写 的实现,不讨论 写-写 的实现。
而多版本并发控制(MVCC)是一种用来解决 读-写冲突 的无锁并发控制。
注意:理解
MVCC必须先理解几个周边知识。
- 事务的
ID- 三个隐藏字段
undo日志
4.1.事务的 ID
为事务分配单向增长的事务 ID,为每个修改保存一个版本,版本与事务 ID 关联,读操作只读该事务开始前的数据快照,所以 MVCC 可以为数据库解决:
- 并发读写数据库时,可以做到在 (1)读操作时不用阻塞写操作 (2)写操作时不用阻塞读操作 提高了数据库并发读写的性能
- 同时可以解决: (1)脏读(未提交就可以被其他客户端读取) (2)幻读(在多次查询的过程中查出更加新的数据) (3)不可重复读(对方客户端提交,本客户端就会立刻看到更新结果)
事务 ID 越小,事务到来的顺序越靠前。
MySQL 底层是 C/C++ 编写的,因此内部事务也一定是有对应的结构体/类,内部有事务的属性和方法,再生成事务实例进行组织(使用特点的数据结构进行组织)。
而事务 ID 也一定是事务结构体内部的属性之一,此外还有其他的属性。
4.2.三个隐藏字段
在数据表中,隐藏三个字段:
DB_TRX_ID:6 byte,记录创建这条记录,且最后一次修改(修改/插入)该记录的事务ID(因此很容易对操作进行溯源)DB_ROLL_PTR:7 byte,回滚指针,指向这条记录的上一个版本(简单理解成指向历史版本,这些数据一般都在undo log中。MySQL在修改一条记录的时候,仍会保留该记录,然后再复制一份去修改,有点类似“写时拷贝”)DB_ROW_ID:6 byte,隐含的自增ID(也就是我们以前在索引里提到的隐藏主键),如果数据表没有主键,InnoDB会自动以DB_ROW_ID产生一个聚簇索引(而如果用户设定了主键,就会导致该字段无效,因为一个表只能有一个主键)FLAG:记录被更新或删除并不代表真的删除,而是flag变了,等到刷盘的时候再修改磁盘内的数据,并且如果希望恢复,也可以恢复该字段,达到恢复数据有效性的
4.3.undo 日志
在提及 undo 日志之前,我们还需要提及下 MySQL 里的日志模块,undo 就是撤销的意思,本质是 MySQL 使用 new/malloc() 申请出来的一块内存空间,在内存种运行,临时性非常高。
补充:我们之前提及的所有机制,索引、事务、隔离性、日志等,都是在内存种完成的操作,然后在特定的时候进行刷盘。
4.4.模拟 MVCC
# 创建一个用于解释的表结构
mysql> create table if not exists student(
-> name varchar(11) not null,
-> age int not null
-> );
Query OK, 0 rows affected (0.04 sec)假设创建了上述表结构,此时数据表字段结构如下:
| name | age | DB_TRX_ID(创建对应记录的事务 ID) | DB_ROW_ID(隐式主键) | DB_ROLL_PTR(回滚指针) |
|---|---|---|---|---|
| limou | 18 | 9(假设是 9 号 ID 的事务插入的) | 1 | null |
现在有一个事务 ID=10 的事务,封装内含操作为:修改 name='limou' 为 name='dimou' 的 SQL 语句。
在修改前,先将原本未修改的记录 [limou,18,9,1,null] 加锁,然后保存/拷贝一份,放入 undo log,给予这条被保存的记录一个内存地址,假设是 0xaa。
此时回到原来的记录,现在要对其进行修改:
DB_ROLL_PTR=null变为DB_ROLL_PTR=0xaa,这就是保存了一个版本name='limou'变为name='daimou'DB_TRX_ID=9变为DB_TRX_ID=10DB_ROW_ID=1变为DB_ROW_ID=2
最后进行 COMMIT 时,释放该记录的锁,因此修改记录是原子的,保证串行化。
| name | age | DB_TRX_ID(创建对应记录的事务 ID) | DB_ROW_ID(隐式主键) | DB_ROLL_PTR(回滚指针) |
|---|---|---|---|---|
| dimou | 18 | 10 | 2 | 0xaa |
假设这个时候又有一个事务 ID=11 的事务,该事务修改 age=28。也是要修改记录,那这条记录是哪一个记录的呢?首先排除历史记录,历史记录必须是稳定的,最好一次写入的。
因此只能改最新的记录,能直接改么?不能!需要先复制一份记录 [dimou,18,10,2,0xaa] 到 undo log 中,然后再进行和第一次插入记录时一样的操作。
注意:此时在
undo log中的历史记录的字段DB_ROLL_PTR是相互链接的,形成版本链链表。
| name | age | DB_TRX_ID(创建对应记录的事务 ID) | DB_ROW_ID(隐式主键) | DB_ROLL_PTR(回滚指针) |
|---|---|---|---|---|
| dimou | 28 | 11 | 3 | 0xbb |
而所谓的回滚操作,不就是对版本链链表的操作么(当然,肯定还有很多其他细节,这里不敢细细深究,我们这里简单来理解就行)。
补充:实际上回滚时,不是直接把历史记录覆盖到数据表中的,而是和操作记录相反的
SQL语句,如果需要回滚,只需要执行这些相反的操作就可以了(用户进行插入,MySQL就记录一条相反的删除语法,方便以后回滚数据)。
上面的版本链模型就是 多版本并发控制(MVCC) 的体现,其中每一个版本我们习惯称为一个 快照。
那如果操作过多,undo log 会不会被塞满呢?首先 undo log 是一个内存级的。对于一个事务来说,一旦被 COMMIT 就会被 delete/free() 释放空间,内部的快照也会被清除(这也就是为什么 COMMIT 后的事务无法回滚的原因)。
那在什么时候会持续保存快照数据?多事务的时候,有的时候访问的不是最新记录,而是历史记录(undo log 主要是配合隔离性设置的)。
那如果删除数据呢?简单,设置 flag 就行,也是形成版本链/快照。
那插入怎么办?数据表中本来就没有,那是怎么回滚的呢?记录和 insert 相反的 delete 操作即可,同样可以形成版本链/快照。
那 select 呢?其本身只是查看数据表中的记录,版本记录没有意义,但是会有一个问题:select 该去查看哪一个版本的快照呢?
首先我们定义读的方式:
- 当前读:读取到最新的数据,增删改数据表都涉及到当前读,而
select有可能是当前读 - 快照读:读取到快照/历史版本就叫做快照读,一般是
select在快照读
读写并发时,如果是读取不同版本数据表,并且设置了隔离级别,这就注定是读取不同资源,也就无需加锁,因此就可以并发进行读写操作(当然,如果都是读操作都是当前读,也还是需要加锁的,因为是同一份最新的资源)。
基本数据被其他客户端改了,只要读取的版本固定,就一定不会让不同的读取受到影响,进一步就是发生了隔离,这种就是在“版本上做隔离”!
而隔离级别的设置,就是对一个事务使用 select 能看到哪一个版本的设置。到此,隔离性会让所有并发执行事务看到不同的数据的基础也就找出来了(这是一个即提高效率,又为后续隔离性做铺垫的非常完美的方案)。
因此隔离性、回滚,都是基于 MVCC 来控制、设置的。
而串行化实际上就可以简单理解为,读写操作都要求加锁,导致事务变得串行化。
为什么设置不同的隔离级别?首先事务是原子的,一定有先后顺序,从 BEGIN 到 COMMIT 一定是有一个过程的,多个事务中,让不同的事务看到它那个时间点该看到的数据(至于看到什么信息,是需要根据情况来抉择的,进而选择不同的隔离级别)。
4.5.Read View
Read View 就是事物进行快照读操作时生产的读视图,在事物执行的快照读那一刻,会生成数据库系统中一个快照,记录并维护系统当前活跃事务的 ID,这个 ID 是递增,所以最新的事务 ID 值越大。
而 Read View 在 MySQL 源码中体现为一个类,本质就是一个结构体/类描述,用来进行可见性判断。当我们某个事务执行快照读的时候,会对该记录创建一个 Read View 读视图,可以把它的整体比作一个条件,用来判断当前事务能够看到哪个版本的数据,既可以是当前最新的数据,也可以是 undo log 里某个版本的数据。
//读视窗结构体
class ReadView
{
private:
trx_id_t m_up_limit_id; //低水位(没写错),小于等于这个 ID 的事务均可见
trx_id_t m_low_limit_id; //高水位(没写错),大于等于这个 ID 的事务均不可见
trx_id_t m_creator_trx_id; //创建该 Read View 对象的事务 ID
ids_t m_ids; //创建视图时的其他一起活跃事务的 ID 列表
//up_limit_id:记录 m_ids 列表中事务 ID 最小的 ID(没有写错)
//low_limit_id:Read View 生成时刻系统尚未分配的下一个事务 ID,就是目前已出现事务 ID 的最大值 +1(没有写错),不是事务最大值 +
trx_id_t m_low_limit_no; //配合 purge 值,了解一下就行,我们不关心
bool m_closed; //标记视图是否被关闭,也不太关心
};补充:可以尝试使用进程结构体来类比事务结构体,而进程地址空间类比读视图。
而 只有首次 某个事务执行快照读的时候,才会对该记录创建一个 Read View 读视图(进程也是类似)。
我们再实际读取版本链的时候,是能读取到每个版本对于的事务 ID 的,即 DB_TRX_ID 字段的信息。
那么现在的工作就是将 DB_TRX_ID 和 ReadView{/*...*/}; 做比较,来得到事务是否可见的判断。
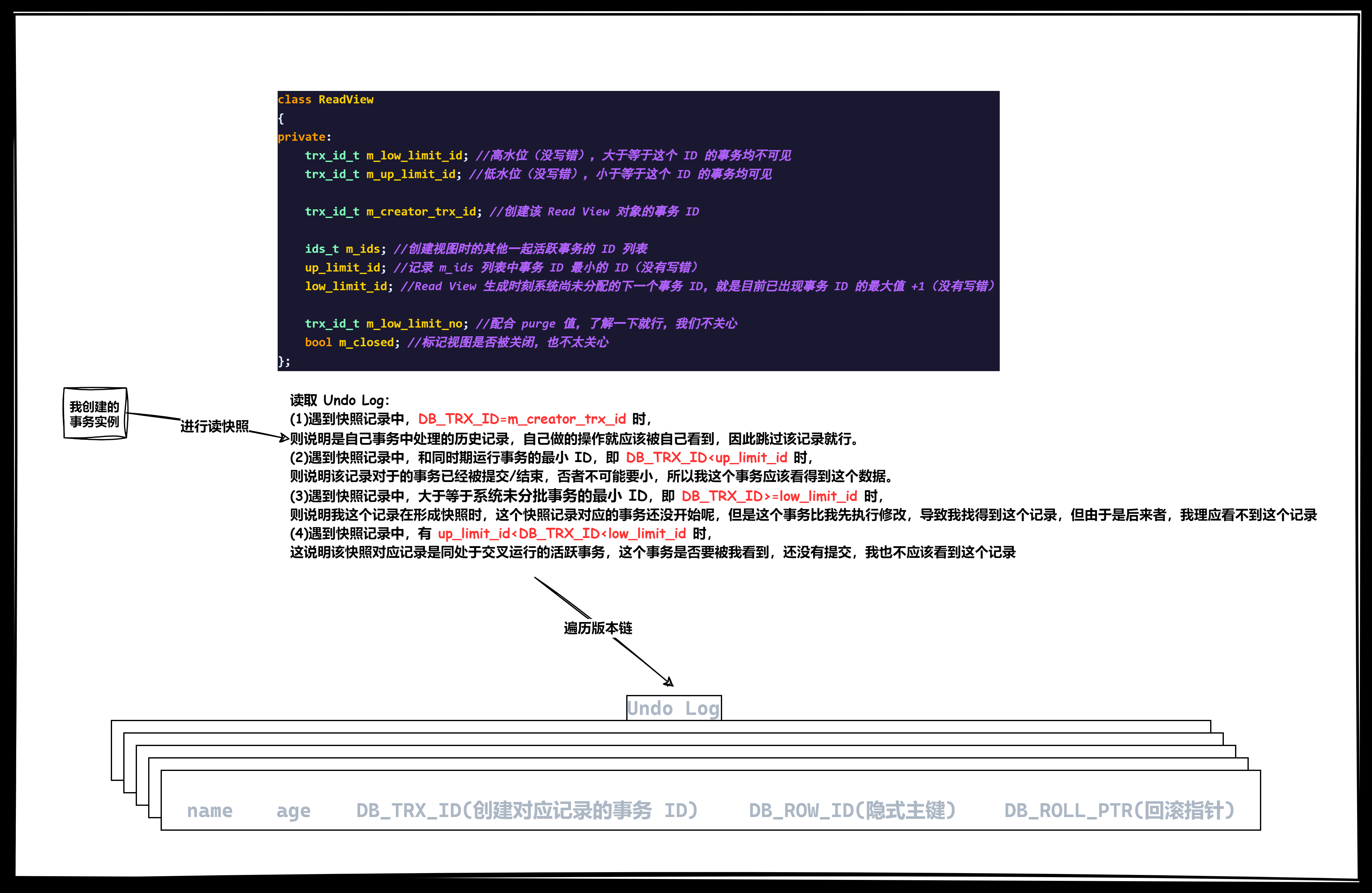
读取 Undo Log 的那一刻生成读视图: (1)遇到快照记录中,DB_TRX_ID=m_creator_trx_id 时, 则说明是自己事务中处理的历史记录,自己做的操作就应该被自己 看到,因此跳过该记录就行。 (2)遇到快照记录中,和同时期运行事务的最小 ID,即 DB_TRX_ID<up_limit_id 时, 则说明该记录对于的事务已经被提交/结束,否者不可能要小,所以我这个事务应该 看到 这个数据。 (3)遇到快照记录中,大于等于系统未分批事务的最小 ID,即 DB_TRX_ID>=low_limit_id 时, 则说明我这个记录在形成快照时,这个快照记录对应的事务还没开始呢,但是这个事务比我先执行修改,导致我找得到这个记录,但由于是后来者,我理应 看不到 这个记录 (4)遇到快照记录中,有 up_limit_id<DB_TRX_ID<low_limit_id 时, 这说明该快照对应记录是同处于交叉运行的活跃事务,这个事务是否要被我看到,还没有提交,我也 看不到 这个记录。
4.6.实际操作
假设当前学生表内有记录如下:
| name | age | DB_TRX_ID(创建对应记录的事务 ID) | DB_ROW_ID(隐式主键) | DB_ROLL_PTR(回滚指针) |
|---|---|---|---|---|
| limou | 18 | 0 | 1 | 0xaa |
然后又如下几个事务:
| 时间点 | 事务 1 [id = 1] | 事务 2 [id = 1] | 事务 3 [id = 1] | 事务 4 [id = 1] |
|---|---|---|---|---|
| 1 | 事务开始 | 事务开始 | 事务开始 | 事务开始 |
| 2 | 交叉... | 交叉... | 交叉... | 修改提交 'limou'->'dimou' |
| 3 | 进行中 | 快照读 | 进行中 | |
| 4 | ... | ... | ... |
注意:
ID值越小的事务越先被启动,这点需要注意。
事务
4成功修改name='dimou',并且生成对应的版本链
a97981ed798f4d965aad3ceb6ada95a 事务
2对某行执行了快照读,此时数据库为改行数据生成一个Read View读视图,其内部属性值如下://事务2的 Read View m_ids; //[1,3] up_limit_id; //1 low_limit_id; //4+1=5,注意是系统未分配的最近的事务 ID creator_trx_id; //本事务的事务 ID=2上述属性会从
DB_ROW_ID=2开始遍历版本链进行比对,事务二能不能看到事务四的提交呢(先不考虑隔离级别,直接按照我本小节的理解)?遍历快照可以确定,快照不对应事务的
ID值四种情况,如果可以看到,这就是读提交RC的隔离级别
那 RC 究竟和 RR 有什么区别呢(分别指 READ COMMITTED/REPEATABLE READ)?
首先您需要知道,指令 SELECT * FROM table_name LOCK IN SHARE MODE; 就是当前读,而不是您以前使用 SELECT 时默认的快照读,然后我们做一个实验:
# 设置为 RR 模式
mysql> set global transaction isolation level REPEATABLE READ;
Query OK, 0 rows affected (0.00 sec)
# 重启终端查看是否更改
mysql> select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set, 1 warning (0.00 sec)
# 创建测试用的表
create table if not exists account(
id int primary key,
name varchar(50) not null default '',
age int
)ENGINE=InnoDB DEFAULT CHARSET=UTF8;
# 插入一些记录,用来测试
mysql> insert into account (id, name, age) values (1, 'iimou', 15);
Query OK, 1 row affected (0.00 sec)| 事务 A | 事务 B |
|---|---|
begin; 事务开始 | begin; 事务开始 |
| 交叉... | 交叉... |
select * from account; 快照读(无影响) | select * from account; (此时第一次形成了 Read View 快照读,认为 A 和自己是一块运行的) |
update account set age=18 where id = 1;(更新) | - |
commit; | - |
| - | select * from account; 快照读(没读到 age=18) |
| - | select * from account lock in share mode; 当前读(读到了 age=18) |
再来做一个测试:
| 事务 A | 事务 B |
|---|---|
begin; (事务开始) | begin; (事务开始) |
| 交叉... | 交叉... |
select * from account; | - |
update account set age=28 where id = 1;(更新) | - |
commit; | - |
| - | select * from account; (只在这个时候生成 Read View,读到 age=28,B 不认为 A 和自己同时活跃) |
| - | select * from account lock in share mode;(读到了 age=28) |
欸,不是可重复读吗?为什么会被修改呢?如果你是事务 B,你自己一直不查你哪里知道数据库里是什么?只需要保证你从第一次读取的时候到最后退出时,都是读取到同一个数据就行了。在那之前,改了什么根本不需要关系。
因此这里就可以得到一个结论:Read View 形成的时机会影响可见性。
因此 RR 和 RC 的深层区别是 Read View 形成时机不同。
在
RR级别下的某个事务的对某条记录的第一次快照读会创建一个快照及Read View,将当前系统活跃的其他事务记录起来。此后在调用快照读的时候,还是使用的是同一个
Read View,所以只要当前事务在其他事务提交更新之前使用过快照读,那么之后的快照读使用的都是同一个Read View,所以对之后的修改不可见。RR级别下,快照读生成Read View时,Read View会记录此时所有其他活动事务的快照,这些事务的修改对于当前事务都是不可见的。而早于Read View创建的事务所做的修改均是可见。而在
RC级别下的,事务中,每次快照读都会新生成一个快照和Read View,这就是我们在RC级别下的事务中可以看到别的事务提交的更新的原因。总之在RC隔离级别下,是每个快照读都会生成并获取最新的Read View。所以,RC才会有不可重复读问题。
补充:建议再看一遍,待补充...